Res
El objetivo de este post es exponer las principales funciones del paquete {dplyr} diseñadas para la manipulación de dataframes/tibbles. Utilizamos el dataframe ‘babynames’ del paquete babynames().
¿Qué es dplyr?
dplyr es un paquete compuesto por un conjunto de funciones diseñado por Hadley Wickham para la manipulación de data frames, y forma parte del conjunto de paquetes conocido como The tidyverse. En particular, como veremos a continuación, dplyr constituye en un conjunto de herramientas que facilita en gran medida la manipulación de data frames.
Las funciones del paquete {dplyr} son las siguientes:
select()filter()group_by()mutate()summarise()arrange()
En primer lugar debemos instalar y cargar el paquete {dplyr}
library(dplyr)
Por lo general, el primer argumento de estas funciones es el dataframe utilizado, al que sigue los parámetros requeridos para realizar las operaciones. No obstante, una forma sencilla de utilizar las funciones del paquete {dplyr} es utilizando pipes (%>%), encadenando de esta forma distintas funciones en un mismo código. Para ello, se establece en primer lugar el data frame a utilizar, seguido del operador %>% y, a continuación, la función y los parámetros necesarios. Los ejemplos utilizados en este post utilizarán pipes.
babynames
En este post utilizaremos el dataframe (tibble) babynames, incluido en el paquete llamado también {babynames}. Dicho dataframe contiene información por nombre de las personas recién nacidas en Estados Unidos para cada año desde 1880 hasta 2017 (aunque descarta los nombres de menos de seis observaciones), proporcionado por la Agencia de Seguridad Social norteamericana. El data frame se compone de 1.924.655 mill de filas y 5 columnas: year, sex, name, n y prop, donde prop es la proporción de personas de dicho género con el nombre indicado en el año correspondiente.
library(babynames)
library(fansi)
Por consiguiente, la estructura del data frame es:
str(babynames)
## tibble [1,924,665 x 5] (S3: tbl_df/tbl/data.frame)
## $ year: num [1:1924665] 1880 1880 1880 1880 1880 1880 1880 1880 1880 1880 ...
## $ sex : chr [1:1924665] "F" "F" "F" "F" ...
## $ name: chr [1:1924665] "Mary" "Anna" "Emma" "Elizabeth" ...
## $ n : int [1:1924665] 7065 2604 2003 1939 1746 1578 1472 1414 1320 1288 ...
## $ prop: num [1:1924665] 0.0724 0.0267 0.0205 0.0199 0.0179 ...
Donde las primeras diez observaciones de babynames son los nombres más comunes en el primer año del periodo, es decir, 1880.
head(babynames, n=10)
## # A tibble: 10 x 5
## year sex name n prop
## <dbl> <chr> <chr> <int> <dbl>
## 1 1880 F Mary 7065 0.0724
## 2 1880 F Anna 2604 0.0267
## 3 1880 F Emma 2003 0.0205
## 4 1880 F Elizabeth 1939 0.0199
## 5 1880 F Minnie 1746 0.0179
## 6 1880 F Margaret 1578 0.0162
## 7 1880 F Ida 1472 0.0151
## 8 1880 F Alice 1414 0.0145
## 9 1880 F Bertha 1320 0.0135
## 10 1880 F Sarah 1288 0.0132
# Mary lidera el ranking en dicho año, seguido por Anna, Emma y Elizabeth. En los primeros diez puestos no encontramos nombres masculinos.
select()
Supongamos que no queremos conservar todas las columnas del data frame original. En nuestro caso particular supongamos que únicamente queremos trabajar con las columnas year, sex y name. En ese caso podemos seleccionar dichas columnas de la siguiente forma:
# Seleccionando las columnas year, sex y name:
babynames %>%
select(year, sex, name)
## # A tibble: 1,924,665 x 3
## year sex name
## <dbl> <chr> <chr>
## 1 1880 F Mary
## 2 1880 F Anna
## 3 1880 F Emma
## 4 1880 F Elizabeth
## 5 1880 F Minnie
## 6 1880 F Margaret
## 7 1880 F Ida
## 8 1880 F Alice
## 9 1880 F Bertha
## 10 1880 F Sarah
## # ... with 1,924,655 more rows
Otras formas alternativas para obtener el mismo resultado sería utilizando el operador :, que nos permite seleccionar las variables que se encuentran entre las dos columnas seleccionadas o, también, eliminando las dos últimas columnas mediante el uso de un signo negativo.
# seleccionando las columnas que se encuentran entre las columnas year y name:
babynames %>%
select(year:name)
## # A tibble: 1,924,665 x 3
## year sex name
## <dbl> <chr> <chr>
## 1 1880 F Mary
## 2 1880 F Anna
## 3 1880 F Emma
## 4 1880 F Elizabeth
## 5 1880 F Minnie
## 6 1880 F Margaret
## 7 1880 F Ida
## 8 1880 F Alice
## 9 1880 F Bertha
## 10 1880 F Sarah
## # ... with 1,924,655 more rows
# eliminando las columnas que se encuentran entre n y prop:
babynames %>%
select(-(n:prop))
## # A tibble: 1,924,665 x 3
## year sex name
## <dbl> <chr> <chr>
## 1 1880 F Mary
## 2 1880 F Anna
## 3 1880 F Emma
## 4 1880 F Elizabeth
## 5 1880 F Minnie
## 6 1880 F Margaret
## 7 1880 F Ida
## 8 1880 F Alice
## 9 1880 F Bertha
## 10 1880 F Sarah
## # ... with 1,924,655 more rows
En el caso de que fuese requerido cambiar el nombre de todas o alguna de las columnas seleccionadas se puede hacer de forma sencilla como se observa en la siguiente orden:
babynames %>%
select(year, sexo= sex, nombre = name, num = n)
## # A tibble: 1,924,665 x 4
## year sexo nombre num
## <dbl> <chr> <chr> <int>
## 1 1880 F Mary 7065
## 2 1880 F Anna 2604
## 3 1880 F Emma 2003
## 4 1880 F Elizabeth 1939
## 5 1880 F Minnie 1746
## 6 1880 F Margaret 1578
## 7 1880 F Ida 1472
## 8 1880 F Alice 1414
## 9 1880 F Bertha 1320
## 10 1880 F Sarah 1288
## # ... with 1,924,655 more rows
# Para renombrar las columnas sin necesidad de seleccionarlas podemos hacer uso de la función rename()
filter()
La función filter() permite seleccionar un conjunto de observaciones según un parámetro determinado. Por ejemplo, supongamos que nos interesa seleccionar únicamente las observaciones correspondientes al año 2017. En dicho caso podemos escribir el siguiente código:
babynames %>%
filter(year== 2017)
## # A tibble: 32,469 x 5
## year sex name n prop
## <dbl> <chr> <chr> <int> <dbl>
## 1 2017 F Emma 19738 0.0105
## 2 2017 F Olivia 18632 0.00994
## 3 2017 F Ava 15902 0.00848
## 4 2017 F Isabella 15100 0.00805
## 5 2017 F Sophia 14831 0.00791
## 6 2017 F Mia 13437 0.00717
## 7 2017 F Charlotte 12893 0.00688
## 8 2017 F Amelia 11800 0.00629
## 9 2017 F Evelyn 10675 0.00569
## 10 2017 F Abigail 10551 0.00563
## # ... with 32,459 more rows
# En 2017 Emma sigue siendo uno de los nombres más recurrentes, ocupando el primer puesto del ranking. Por el contrario, nuevos nombres como Olivia, Ava, Sophia, etc., aparecen en el nuevo ranking. Al igual que sucedía en 1880 seguimos sin encontrar nombres masculinos en el top 10.
# Podemos seleccionar varios años con el comando %in%
babynames %>%
filter(year %in% c(1880, 1900, 1920, 1940, 1960, 1980, 2000))
## # A tibble: 86,581 x 5
## year sex name n prop
## <dbl> <chr> <chr> <int> <dbl>
## 1 1880 F Mary 7065 0.0724
## 2 1880 F Anna 2604 0.0267
## 3 1880 F Emma 2003 0.0205
## 4 1880 F Elizabeth 1939 0.0199
## 5 1880 F Minnie 1746 0.0179
## 6 1880 F Margaret 1578 0.0162
## 7 1880 F Ida 1472 0.0151
## 8 1880 F Alice 1414 0.0145
## 9 1880 F Bertha 1320 0.0135
## 10 1880 F Sarah 1288 0.0132
## # ... with 86,571 more rows
Pongamos que nos interesa seleccionar solo los nombres de sexo masculino (M), para ello indicaríamos el siguiente comando:
babynames %>%
filter(sex== "M")
## # A tibble: 786,372 x 5
## year sex name n prop
## <dbl> <chr> <chr> <int> <dbl>
## 1 1880 M John 9655 0.0815
## 2 1880 M William 9532 0.0805
## 3 1880 M James 5927 0.0501
## 4 1880 M Charles 5348 0.0452
## 5 1880 M George 5126 0.0433
## 6 1880 M Frank 3242 0.0274
## 7 1880 M Joseph 2632 0.0222
## 8 1880 M Thomas 2534 0.0214
## 9 1880 M Henry 2444 0.0206
## 10 1880 M Robert 2415 0.0204
## # ... with 786,362 more rows
# Nombres clásicos aparecen en el ranking masculino. John, William, James, Charles o George se sitúan como los nombres más populares en 1880.
En el caso de que quisiéramos seleccionar los nombres de sexo masculino para un año determinado anotaríamos el siguiente código:
babynames %>%
filter(year == 2017 & sex == "M")
## # A tibble: 14,160 x 5
## year sex name n prop
## <dbl> <chr> <chr> <int> <dbl>
## 1 2017 M Liam 18728 0.00954
## 2 2017 M Noah 18326 0.00933
## 3 2017 M William 14904 0.00759
## 4 2017 M James 14232 0.00725
## 5 2017 M Logan 13974 0.00712
## 6 2017 M Benjamin 13733 0.00699
## 7 2017 M Mason 13502 0.00688
## 8 2017 M Elijah 13268 0.00676
## 9 2017 M Oliver 13141 0.00669
## 10 2017 M Jacob 13106 0.00668
## # ... with 14,150 more rows
# Se observa un cambio significativo en las preferencias de los nombres de los recién nacidos. Liam, Noah, Logan aparecen en el ranking, aunque algunos nombres más tradicionales, como William o James, conservan todavía su atractivo.
O supongamos que nos interesa seleccionar los nombres de cualquier sexo que hayan superado los 9000 registros y determinar el año en el que esto sucedió
babynames %>%
filter(n > 9000)
## # A tibble: 6,653 x 5
## year sex name n prop
## <dbl> <chr> <chr> <int> <dbl>
## 1 1880 M John 9655 0.0815
## 2 1880 M William 9532 0.0805
## 3 1882 M John 9557 0.0783
## 4 1882 M William 9298 0.0762
## 5 1884 F Mary 9217 0.0670
## 6 1884 M John 9388 0.0765
## 7 1885 F Mary 9128 0.0643
## 8 1886 F Mary 9889 0.0643
## 9 1886 M John 9026 0.0758
## 10 1887 F Mary 9888 0.0636
## # ... with 6,643 more rows
Otra posibilidad sería, por ejemplo, filtrar el conjunto de observaciones con el objetivo de identificar el número de niños de sexo masculino que recibieron un nombre determinado para cada uno de los años del periodo. Pongamos, por ejemplo, que queremos determinar cuántos recién nacidos recibieron el nombre de Ruben (sin tilde) para cada uno de los años entre 1880 y 2017.
# Guardamos el nuevo data frame con el nombre Ruben
Ruben <- babynames %>%
filter(sex == "M" & name == "Ruben")
# el paquete knitr permite hacer tablas utilizando la función kable()
library(knitr)
knitr::kable(Ruben)| year | sex | name | n | prop |
|---|---|---|---|---|
| 1880 | M | Ruben | 30 | 0.0002534 |
| 1881 | M | Ruben | 21 | 0.0001939 |
| 1882 | M | Ruben | 34 | 0.0002786 |
| 1883 | M | Ruben | 30 | 0.0002667 |
| 1884 | M | Ruben | 28 | 0.0002281 |
| 1885 | M | Ruben | 28 | 0.0002415 |
| 1886 | M | Ruben | 40 | 0.0003360 |
| 1887 | M | Ruben | 34 | 0.0003110 |
| 1888 | M | Ruben | 21 | 0.0001617 |
| 1889 | M | Ruben | 33 | 0.0002772 |
| 1890 | M | Ruben | 25 | 0.0002088 |
| 1891 | M | Ruben | 25 | 0.0002288 |
| 1892 | M | Ruben | 44 | 0.0003347 |
| 1893 | M | Ruben | 41 | 0.0003387 |
| 1894 | M | Ruben | 33 | 0.0002642 |
| 1895 | M | Ruben | 37 | 0.0002922 |
| 1896 | M | Ruben | 49 | 0.0003796 |
| 1897 | M | Ruben | 42 | 0.0003444 |
| 1898 | M | Ruben | 45 | 0.0003406 |
| 1899 | M | Ruben | 32 | 0.0002778 |
| 1900 | M | Ruben | 50 | 0.0003084 |
| 1901 | M | Ruben | 35 | 0.0003028 |
| 1902 | M | Ruben | 45 | 0.0003390 |
| 1903 | M | Ruben | 50 | 0.0003866 |
| 1904 | M | Ruben | 38 | 0.0002743 |
| 1905 | M | Ruben | 41 | 0.0002862 |
| 1906 | M | Ruben | 52 | 0.0003609 |
| 1907 | M | Ruben | 62 | 0.0003910 |
| 1908 | M | Ruben | 60 | 0.0003606 |
| 1909 | M | Ruben | 71 | 0.0004014 |
| 1910 | M | Ruben | 83 | 0.0003980 |
| 1911 | M | Ruben | 59 | 0.0002444 |
| 1912 | M | Ruben | 134 | 0.0002968 |
| 1913 | M | Ruben | 154 | 0.0002872 |
| 1914 | M | Ruben | 199 | 0.0002912 |
| 1915 | M | Ruben | 256 | 0.0002906 |
| 1916 | M | Ruben | 237 | 0.0002567 |
| 1917 | M | Ruben | 289 | 0.0003012 |
| 1918 | M | Ruben | 286 | 0.0002727 |
| 1919 | M | Ruben | 292 | 0.0002876 |
| 1920 | M | Ruben | 336 | 0.0003052 |
| 1921 | M | Ruben | 357 | 0.0003137 |
| 1922 | M | Ruben | 361 | 0.0003208 |
| 1923 | M | Ruben | 368 | 0.0003250 |
| 1924 | M | Ruben | 398 | 0.0003404 |
| 1925 | M | Ruben | 427 | 0.0003708 |
| 1926 | M | Ruben | 440 | 0.0003841 |
| 1927 | M | Ruben | 478 | 0.0004114 |
| 1928 | M | Ruben | 493 | 0.0004320 |
| 1929 | M | Ruben | 484 | 0.0004370 |
| 1930 | M | Ruben | 516 | 0.0004569 |
| 1931 | M | Ruben | 465 | 0.0004348 |
| 1932 | M | Ruben | 469 | 0.0004366 |
| 1933 | M | Ruben | 398 | 0.0003902 |
| 1934 | M | Ruben | 443 | 0.0004172 |
| 1935 | M | Ruben | 488 | 0.0004563 |
| 1936 | M | Ruben | 482 | 0.0004529 |
| 1937 | M | Ruben | 489 | 0.0004472 |
| 1938 | M | Ruben | 445 | 0.0003916 |
| 1939 | M | Ruben | 450 | 0.0003971 |
| 1940 | M | Ruben | 443 | 0.0003735 |
| 1941 | M | Ruben | 462 | 0.0003682 |
| 1942 | M | Ruben | 512 | 0.0003636 |
| 1943 | M | Ruben | 544 | 0.0003741 |
| 1944 | M | Ruben | 506 | 0.0003643 |
| 1945 | M | Ruben | 560 | 0.0004084 |
| 1946 | M | Ruben | 648 | 0.0003927 |
| 1947 | M | Ruben | 737 | 0.0003968 |
| 1948 | M | Ruben | 909 | 0.0005099 |
| 1949 | M | Ruben | 997 | 0.0005533 |
| 1950 | M | Ruben | 1025 | 0.0005635 |
| 1951 | M | Ruben | 1040 | 0.0005440 |
| 1952 | M | Ruben | 1098 | 0.0005562 |
| 1953 | M | Ruben | 1202 | 0.0006006 |
| 1954 | M | Ruben | 1259 | 0.0006087 |
| 1955 | M | Ruben | 1290 | 0.0006173 |
| 1956 | M | Ruben | 1366 | 0.0006370 |
| 1957 | M | Ruben | 1382 | 0.0006318 |
| 1958 | M | Ruben | 1375 | 0.0006386 |
| 1959 | M | Ruben | 1358 | 0.0006269 |
| 1960 | M | Ruben | 1359 | 0.0006275 |
| 1961 | M | Ruben | 1382 | 0.0006410 |
| 1962 | M | Ruben | 1380 | 0.0006565 |
| 1963 | M | Ruben | 1259 | 0.0006096 |
| 1964 | M | Ruben | 1345 | 0.0006634 |
| 1965 | M | Ruben | 1150 | 0.0006068 |
| 1966 | M | Ruben | 1198 | 0.0006590 |
| 1967 | M | Ruben | 1175 | 0.0006602 |
| 1968 | M | Ruben | 1139 | 0.0006413 |
| 1969 | M | Ruben | 1237 | 0.0006760 |
| 1970 | M | Ruben | 1326 | 0.0006958 |
| 1971 | M | Ruben | 1322 | 0.0007270 |
| 1972 | M | Ruben | 1323 | 0.0007900 |
| 1973 | M | Ruben | 1310 | 0.0008115 |
| 1974 | M | Ruben | 1383 | 0.0008481 |
| 1975 | M | Ruben | 1376 | 0.0008478 |
| 1976 | M | Ruben | 1365 | 0.0008358 |
| 1977 | M | Ruben | 1365 | 0.0007983 |
| 1978 | M | Ruben | 1379 | 0.0008069 |
| 1979 | M | Ruben | 1398 | 0.0007802 |
| 1980 | M | Ruben | 1488 | 0.0008022 |
| 1981 | M | Ruben | 1473 | 0.0007909 |
| 1982 | M | Ruben | 1470 | 0.0007790 |
| 1983 | M | Ruben | 1494 | 0.0008018 |
| 1984 | M | Ruben | 1374 | 0.0007323 |
| 1985 | M | Ruben | 1453 | 0.0007553 |
| 1986 | M | Ruben | 1381 | 0.0007189 |
| 1987 | M | Ruben | 1527 | 0.0007833 |
| 1988 | M | Ruben | 1592 | 0.0007955 |
| 1989 | M | Ruben | 1595 | 0.0007612 |
| 1990 | M | Ruben | 1744 | 0.0008107 |
| 1991 | M | Ruben | 1732 | 0.0008173 |
| 1992 | M | Ruben | 1805 | 0.0008601 |
| 1993 | M | Ruben | 1749 | 0.0008470 |
| 1994 | M | Ruben | 1724 | 0.0008460 |
| 1995 | M | Ruben | 1697 | 0.0008439 |
| 1996 | M | Ruben | 1662 | 0.0008296 |
| 1997 | M | Ruben | 1595 | 0.0007986 |
| 1998 | M | Ruben | 1582 | 0.0007804 |
| 1999 | M | Ruben | 1637 | 0.0008031 |
| 2000 | M | Ruben | 1716 | 0.0008221 |
| 2001 | M | Ruben | 1735 | 0.0008392 |
| 2002 | M | Ruben | 1571 | 0.0007606 |
| 2003 | M | Ruben | 1655 | 0.0007881 |
| 2004 | M | Ruben | 1601 | 0.0007580 |
| 2005 | M | Ruben | 1464 | 0.0006886 |
| 2006 | M | Ruben | 1593 | 0.0007271 |
| 2007 | M | Ruben | 1477 | 0.0006673 |
| 2008 | M | Ruben | 1354 | 0.0006215 |
| 2009 | M | Ruben | 1197 | 0.0005649 |
| 2010 | M | Ruben | 1102 | 0.0005370 |
| 2011 | M | Ruben | 975 | 0.0004806 |
| 2012 | M | Ruben | 957 | 0.0004724 |
| 2013 | M | Ruben | 887 | 0.0004398 |
| 2014 | M | Ruben | 892 | 0.0004363 |
| 2015 | M | Ruben | 862 | 0.0004229 |
| 2016 | M | Ruben | 797 | 0.0003950 |
| 2017 | M | Ruben | 745 | 0.0003795 |
# Vemos que el nombre de Ruben fue incrementando su popularidad en Estados Unidos a lo largo de los años, especialmente hasta 1992, y después, poco a poco, ha ido progresivamente perdiendo su atractivo. No obstante, no parece que Ruben haya sido un nombre muy recurrido en el país a lo largo de estos años.
Como se ha indicado previamente, las pipes %>% sirven especialmente para encadenar funciones, pudiendo reducir el tamaño del código y facilitando su interpretación. Por ejemplo, en el caso de que nos interesara seleccionar únicamente el año y el nombre de los recién nacidos de sexo masculino en el año 2017 indicaríamos:
babynames %>%
select(year, sex, name) %>%
filter(year == 2017 & sex== "M")
## # A tibble: 14,160 x 3
## year sex name
## <dbl> <chr> <chr>
## 1 2017 M Liam
## 2 2017 M Noah
## 3 2017 M William
## 4 2017 M James
## 5 2017 M Logan
## 6 2017 M Benjamin
## 7 2017 M Mason
## 8 2017 M Elijah
## 9 2017 M Oliver
## 10 2017 M Jacob
## # ... with 14,150 more rows
group_by()
La función group_by() convierte el data frame original en una tabla agrupada según los parámetros de la función. La función group_by(), como veremos, funciona muy bien cuando se usa conjuntamente con otras funciones como summarise() o mutate(). Por tanto usaremos esta función conjuntamente con otras funciones en los apartados posteriores pero, a modo de ejemplo, veamos cómo se podría agrupar nuestro data frame según el sexo de los recién nacidos:
# La tabla_1 sería el resultado de agrupar las filas por sexo utilizando group_by()
tabla_1 <- babynames %>%
group_by(sex)
# Una vez agrupada la tabla por sexo, con la función summarise() que veremos después, podemos identificar el número de observaciones según el sexo masculino o femenino del recién nacido.
tabla_1 %>%
summarise(n = n())
## # A tibble: 2 x 2
## sex n
## <chr> <int>
## 1 F 1138293
## 2 M 786372
# Debemos recordar desagrupar las observaciones una vez realizado el análisis necesario utilizando la función ungroup()
tabla_1 <- tabla_1 %>%
ungroup()
# Vemos que una vez hemos desagrupado las observaciones, si aplicamos de nuevo la función summarise() el resultado obtenido es para el conjunto de observaciones y no para las observaciones agrupadas.
tabla_1 %>%
summarise(n = n())
## # A tibble: 1 x 1
## n
## <int>
## 1 1924665
mutate()
La función mutate() nos permite añadir columnas nuevas partiendo de las columnas del data frame original. A modo de ejemplo podemos crear una nueva columna, que denominaremos prop_2, como resultado de multiplicar la columna prop por 100. La función mutate() requiere, una vez indicado el data frame sobre el que se va a operar, que indiquemos el nombre de la nueva columna y la operación que determina el valor de la misma:
babynames %>%
mutate( prop_2 = prop * 100)
## # A tibble: 1,924,665 x 6
## year sex name n prop prop_2
## <dbl> <chr> <chr> <int> <dbl> <dbl>
## 1 1880 F Mary 7065 0.0724 7.24
## 2 1880 F Anna 2604 0.0267 2.67
## 3 1880 F Emma 2003 0.0205 2.05
## 4 1880 F Elizabeth 1939 0.0199 1.99
## 5 1880 F Minnie 1746 0.0179 1.79
## 6 1880 F Margaret 1578 0.0162 1.62
## 7 1880 F Ida 1472 0.0151 1.51
## 8 1880 F Alice 1414 0.0145 1.45
## 9 1880 F Bertha 1320 0.0135 1.35
## 10 1880 F Sarah 1288 0.0132 1.32
## # ... with 1,924,655 more rows
# De esta forma comprobamos de una forma más adecuada que Mary, el nombre femenino más utilizado en 1880, representa el 7,24 del total de nombres de recién nacidos en dicho año.
Supongamos que nos interesa que en una nueva columna se indique el total de las observaciones del conjunto del data frame. En nuestro caso cabe la posibilidad que nos interese crear una nueva columna donde se indique la suma del total de los babynames , es decir, de n, bien sea la suma de todos los años del periodo (1880-2017), bien sea el total según el año. En dicho caso podemos utilizar la función mutate() de la siguiente forma:
# En el primero de los casos la columna sería igual para el total de observaciones, en tanto en cuanto indica el total de n (348120517).
babynames %>%
mutate( suma_total = sum(n))
## # A tibble: 1,924,665 x 6
## year sex name n prop suma_total
## <dbl> <chr> <chr> <int> <dbl> <int>
## 1 1880 F Mary 7065 0.0724 348120517
## 2 1880 F Anna 2604 0.0267 348120517
## 3 1880 F Emma 2003 0.0205 348120517
## 4 1880 F Elizabeth 1939 0.0199 348120517
## 5 1880 F Minnie 1746 0.0179 348120517
## 6 1880 F Margaret 1578 0.0162 348120517
## 7 1880 F Ida 1472 0.0151 348120517
## 8 1880 F Alice 1414 0.0145 348120517
## 9 1880 F Bertha 1320 0.0135 348120517
## 10 1880 F Sarah 1288 0.0132 348120517
## # ... with 1,924,655 more rows
# En el segundo de los casos, agrupando por año, el valor de la columna sería distinta según el año. Así, por ejemplo, para 1880 la suma de n sería 201484.
babynames %>%
group_by(year) %>%
mutate( suma_by_year = sum(n))
## # A tibble: 1,924,665 x 6
## # Groups: year [138]
## year sex name n prop suma_by_year
## <dbl> <chr> <chr> <int> <dbl> <int>
## 1 1880 F Mary 7065 0.0724 201484
## 2 1880 F Anna 2604 0.0267 201484
## 3 1880 F Emma 2003 0.0205 201484
## 4 1880 F Elizabeth 1939 0.0199 201484
## 5 1880 F Minnie 1746 0.0179 201484
## 6 1880 F Margaret 1578 0.0162 201484
## 7 1880 F Ida 1472 0.0151 201484
## 8 1880 F Alice 1414 0.0145 201484
## 9 1880 F Bertha 1320 0.0135 201484
## 10 1880 F Sarah 1288 0.0132 201484
## # ... with 1,924,655 more rows
# Al realizar este tipo de operaciones debemos siempre ser conscientes de los valores que estamos sumando (o con los que estamos operando) para evitar equívocos. Por ello, resulta de gran utilidad utilizar la función summarise() que vemos a continuación.summarise()
La función summarise() provee un valor determinado en función de un conjunto de valores. Así, por ejemplo, para determinar el número de observaciones (filas) del data frame, o para determinar el número total de nacimientos (n) podemos utilizar esta función de la siguiente forma:
babynames %>%
summarise(num_observaciones = n(),
total_babynames = sum(n))
## # A tibble: 1 x 2
## num_observaciones total_babynames
## <int> <int>
## 1 1924665 348120517
# Esta operación nos permite comprobar el total de observaciones y el total de babynames del conjunto del dataframe.
No obstante, la función summarise() tiene una especial utilidad cuando se utiliza conjuntamente con la función group_by(). Así, por ejemplo, podemos estimar fácilmente el número de nacimientos por cada año (o mejor dicho el número de solicitudes de la tarjeta de la SS por nacimiento en Estados Unidos cada año):
babynames %>%
group_by (year) %>%
summarise(suma = sum(n))
## # A tibble: 138 x 2
## year suma
## <dbl> <int>
## 1 1880 201484
## 2 1881 192696
## 3 1882 221533
## 4 1883 216946
## 5 1884 243462
## 6 1885 240854
## 7 1886 255317
## 8 1887 247394
## 9 1888 299473
## 10 1889 288946
## # ... with 128 more rows
# El total del primer deberá coincidir con el valor de la nueva columna creada previamente (suma_by_year) en cada uno de los años del periodo analizado.
De forma similar podemos identificar el número de nacimientos por año y por sexo de los recién nacidos:
babynames %>%
group_by (year, sex) %>%
summarise(suma = sum(n))
## # A tibble: 276 x 3
## # Groups: year [138]
## year sex suma
## <dbl> <chr> <int>
## 1 1880 F 90993
## 2 1880 M 110491
## 3 1881 F 91953
## 4 1881 M 100743
## 5 1882 F 107847
## 6 1882 M 113686
## 7 1883 F 112319
## 8 1883 M 104627
## 9 1884 F 129020
## 10 1884 M 114442
## # ... with 266 more rows
# En los primeros años el registro es mayor en los niños que en las niñas.
También podemos estimar en una sola orden el valor de diversos indicadores. A modo de ejemplo, estimamos para cada año y según el sexo del recién nacido, el total de nacimientos, el valor máximo y el valor mínimo (que previsiblemente será 5 debido a que la base de datos proporciona información de los nombres que superen dicho valor)
babynames %>%
group_by (year, sex) %>%
summarise(suma = sum(n), max = max(n), min = min(n))
## # A tibble: 276 x 5
## # Groups: year [138]
## year sex suma max min
## <dbl> <chr> <int> <int> <int>
## 1 1880 F 90993 7065 5
## 2 1880 M 110491 9655 5
## 3 1881 F 91953 6919 5
## 4 1881 M 100743 8769 5
## 5 1882 F 107847 8148 5
## 6 1882 M 113686 9557 5
## 7 1883 F 112319 8012 5
## 8 1883 M 104627 8894 5
## 9 1884 F 129020 9217 5
## 10 1884 M 114442 9388 5
## # ... with 266 more rows
En el data frame anterior podemos observar las observaciones con mayor valor n en cada año y por sexo, entre otros aspectos. No obstante, puede que nos interese determinar qué nombres lideran el ranking cada año. Para ello podemos establecer el siguiente código:
# Para establecer los nombres (F y M) que lideran el ranking entre 1880 y 1889:
babynames %>%
group_by (year, sex, name) %>%
summarise(max = max(n)) %>%
top_n(1) %>%
head(n=20)
## Selecting by max
## # A tibble: 20 x 4
## # Groups: year, sex [20]
## year sex name max
## <dbl> <chr> <chr> <int>
## 1 1880 F Mary 7065
## 2 1880 M John 9655
## 3 1881 F Mary 6919
## 4 1881 M John 8769
## 5 1882 F Mary 8148
## 6 1882 M John 9557
## 7 1883 F Mary 8012
## 8 1883 M John 8894
## 9 1884 F Mary 9217
## 10 1884 M John 9388
## 11 1885 F Mary 9128
## 12 1885 M John 8756
## 13 1886 F Mary 9889
## 14 1886 M John 9026
## 15 1887 F Mary 9888
## 16 1887 M John 8110
## 17 1888 F Mary 11754
## 18 1888 M John 9247
## 19 1889 F Mary 11648
## 20 1889 M John 8548
# Para establecer los nombres (F y M) que lideran el ranking entre 2008 y 2017:
babynames %>%
group_by (year, sex, name) %>%
summarise(max = max(n)) %>%
top_n(1) %>%
tail(n=20)
## Selecting by max
## # A tibble: 20 x 4
## # Groups: year, sex [20]
## year sex name max
## <dbl> <chr> <chr> <int>
## 1 2008 F Emma 18809
## 2 2008 M Jacob 22591
## 3 2009 F Isabella 22298
## 4 2009 M Jacob 21169
## 5 2010 F Isabella 22905
## 6 2010 M Jacob 22117
## 7 2011 F Sophia 21837
## 8 2011 M Jacob 20365
## 9 2012 F Sophia 22304
## 10 2012 M Jacob 19069
## 11 2013 F Sophia 21213
## 12 2013 M Noah 18241
## 13 2014 F Emma 20924
## 14 2014 M Noah 19286
## 15 2015 F Emma 20435
## 16 2015 M Noah 19613
## 17 2016 F Emma 19471
## 18 2016 M Noah 19082
## 19 2017 F Emma 19738
## 20 2017 M Liam 18728
# Mary y John son, definitivamente, los nombres más recurrentes al inicio del periodo. Por el contrario, en la última década existe una mayor variabilidad en el nombre más escogido tanto para niño como para niña. No obstante, es fácil identificar un grupo de nombres de gran atractivo para la población en estos años, bien sea Emma, Isabella o Sophia para niña o Jacob y Noah para niño.
Una forma alternativa es indicando expresamente que queremos detectar la primera observación del rango deseado, la última o podemos establecer la posición de la observación deseada:
# La primera observación coincidirá con el resultado anterior, siendo Mary y John los nombres más comunes de los primeros años del periodo considerado.
babynames %>%
group_by (year, sex) %>%
summarise(nombre = first(name), max = max(n))
## # A tibble: 276 x 4
## # Groups: year [138]
## year sex nombre max
## <dbl> <chr> <chr> <int>
## 1 1880 F Mary 7065
## 2 1880 M John 9655
## 3 1881 F Mary 6919
## 4 1881 M John 8769
## 5 1882 F Mary 8148
## 6 1882 M John 9557
## 7 1883 F Mary 8012
## 8 1883 M John 8894
## 9 1884 F Mary 9217
## 10 1884 M John 9388
## # ... with 266 more rows
# En este caso particular detectar la observación más baja carece de significado, en tanto en cuanto las observaciones más bajas serán de 5 (mínimo valor de la base de datos), pero puede resultar muy útil en otros análisis
babynames %>%
group_by (year, sex) %>%
summarise(nombre = last(name), min = min(n))
## # A tibble: 276 x 4
## # Groups: year [138]
## year sex nombre min
## <dbl> <chr> <chr> <int>
## 1 1880 F Wilma 5
## 2 1880 M Zachariah 5
## 3 1881 F Viney 5
## 4 1881 M Wright 5
## 5 1882 F Zilla 5
## 6 1882 M Zed 5
## 7 1883 F Zoa 5
## 8 1883 M Winthrop 5
## 9 1884 F Yetta 5
## 10 1884 M Zachariah 5
## # ... with 266 more rows
# Podemos indicar qué valor queremos, pongamos que en lugar de la observación de mayor valor queremos el segundo nombre más utilizado por año y sexo:
babynames %>%
group_by (year, sex) %>%
summarise(nombre = nth(name, 2))
## # A tibble: 276 x 3
## # Groups: year [138]
## year sex nombre
## <dbl> <chr> <chr>
## 1 1880 F Anna
## 2 1880 M William
## 3 1881 F Anna
## 4 1881 M William
## 5 1882 F Anna
## 6 1882 M William
## 7 1883 F Anna
## 8 1883 M William
## 9 1884 F Anna
## 10 1884 M William
## # ... with 266 more rows
# Vemos que tras Mary y John los nombres que lideran el ranking, al menos en los primeros años del periodo, son Anna y William.
También es posible seleccionar las columnas indicando el número de filas. Así, por ejemplo, para seleccionar los dos primeros valores de cada año y sexo podemos indicar la siguiente orden:
babynames %>%
group_by(year, sex) %>%
filter(row_number() <=2)
## # A tibble: 552 x 5
## # Groups: year, sex [276]
## year sex name n prop
## <dbl> <chr> <chr> <int> <dbl>
## 1 1880 F Mary 7065 0.0724
## 2 1880 F Anna 2604 0.0267
## 3 1880 M John 9655 0.0815
## 4 1880 M William 9532 0.0805
## 5 1881 F Mary 6919 0.0700
## 6 1881 F Anna 2698 0.0273
## 7 1881 M John 8769 0.0810
## 8 1881 M William 8524 0.0787
## 9 1882 F Mary 8148 0.0704
## 10 1882 F Anna 3143 0.0272
## # ... with 542 more rows
# Evidentemente, los nombres detectados son los mismos que los obtenidos en los ejercicios previos
arrange()
La función arrange() nos permite ordenar los datos por filas según algún criterio establecido. Pongamos en este caso que queremos ordenar las observaciones por nombre, según un criterio alfabético.
# Para ordenar las filas de la A a la Z:
babynames %>%
arrange(name)
## # A tibble: 1,924,665 x 5
## year sex name n prop
## <dbl> <chr> <chr> <int> <dbl>
## 1 2007 M Aaban 5 0.00000226
## 2 2009 M Aaban 6 0.00000283
## 3 2010 M Aaban 9 0.00000439
## 4 2011 M Aaban 11 0.00000542
## 5 2012 M Aaban 11 0.00000543
## 6 2013 M Aaban 14 0.00000694
## 7 2014 M Aaban 16 0.00000783
## 8 2015 M Aaban 15 0.00000736
## 9 2016 M Aaban 9 0.00000446
## 10 2017 M Aaban 11 0.0000056
## # ... with 1,924,655 more rows
# Para ordenarlas de la Z a la A:
babynames %>%
arrange(desc(name))
## # A tibble: 1,924,665 x 5
## year sex name n prop
## <dbl> <chr> <chr> <int> <dbl>
## 1 2010 M Zzyzx 5 0.00000244
## 2 2014 M Zyyon 6 0.00000293
## 3 2010 F Zyyanna 6 0.00000306
## 4 2015 M Zyvon 7 0.00000343
## 5 2009 M Zyvion 5 0.00000236
## 6 2016 F Zyva 8 0.00000415
## 7 2017 F Zyva 9 0.0000048
## 8 2015 M Zyus 5 0.00000245
## 9 2002 M Zytavious 6 0.0000029
## 10 2004 M Zytavious 6 0.00000284
## # ... with 1,924,655 more rows
# Resulta que Zzyzx, antes llamado Soda Springs, es una comunidad en el Condado de San Bernardino, en el desierto de Mojave en California. Según Wikipedia un tal Curtis Howe Springer se inventó el término y lo dio a dicho espacio, orgulloso de que dicho vocablo fuese la última palabra en el idioma inglés. Parece ser que la revista Reader´s Digest ha declarado a Zzyzx el lugar de California más difícil de pronunciar y que una encuesta de eBabyNames.com dice que Zzyzx (que se pronunciaría algo así como Zay-Zix) sería, según sus encuestados, el nombre más raro que habría existido jamás.
Podemos también organizar las observaciones según otros criterios. Si por ejemplo queremos detectar qué nombres, en qué año y a qué sexo corresponde las observaciones con mayor número de registros. Para ello podemos anotar la siguiente orden:
babynames %>%
arrange(desc(n))
## # A tibble: 1,924,665 x 5
## year sex name n prop
## <dbl> <chr> <chr> <int> <dbl>
## 1 1947 F Linda 99686 0.0548
## 2 1948 F Linda 96209 0.0552
## 3 1947 M James 94756 0.0510
## 4 1957 M Michael 92695 0.0424
## 5 1947 M Robert 91642 0.0493
## 6 1949 F Linda 91016 0.0518
## 7 1956 M Michael 90620 0.0423
## 8 1958 M Michael 90520 0.0420
## 9 1948 M James 88588 0.0497
## 10 1954 M Michael 88514 0.0428
## # ... with 1,924,655 more rows
# En este caso vemos que Linda resultó ser la opción más popular para las niñas en 1947 y 1948, siendo estos años donde más gente coincidió en su decisión.
dplyr y ggplot2
Dado que una imagen vale más que mil palabras conviene tener en cuenta que las funciones del paquete dplyr, utilizando pipes (%) para encadenar funciones, pueden utilizarse conjuntamente con los gráficos de ggplot como se observa en los siguientes ejemplos.
Supongamos que queremos observar la evolución del número total de registros de solicitud de la tarjeta de la Seguridad Social por año, para lo que utilizaremos las funciones group_by() y summarise() seguido de las instrucciones de ggplot2.
# Cargamos la librería ggplot2
library(ggplot2)
babynames %>%
group_by(year) %>%
summarise(suma = sum(n)) %>%
ggplot(aes(x= year, y = suma, fill = "orange")) +
geom_col() +
scale_y_continuous(labels = scales::comma) +
theme_minimal() +
guides(fill=F) +
labs( x= "year",
y= " ",
title = "Número de personas recién nacidas en Estados Unidos desde 1880 a 2017",
subtitle = "Estimado en base al número de solicitudes de la tarjeta de la Seguridad Social",
caption = "US Social Security Administration")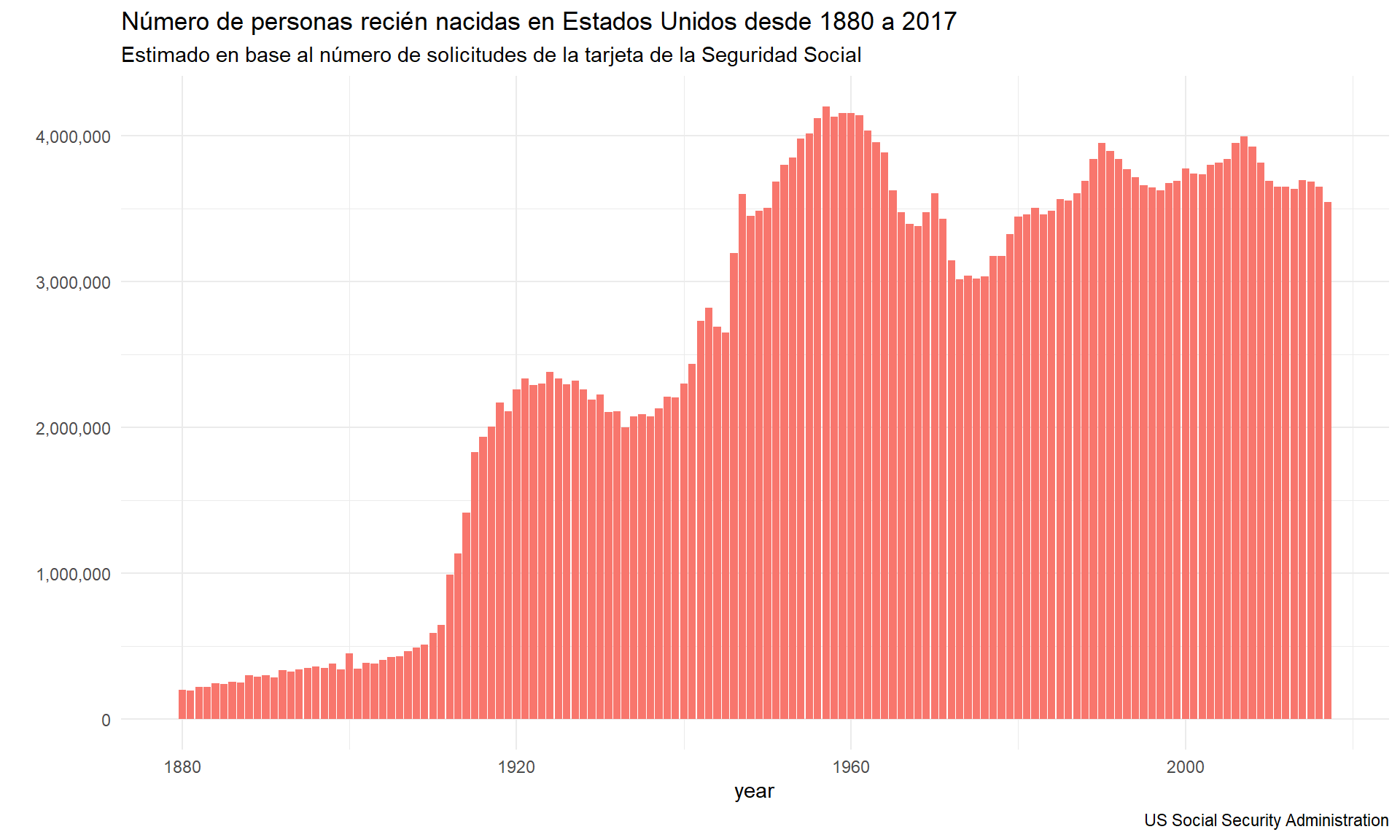
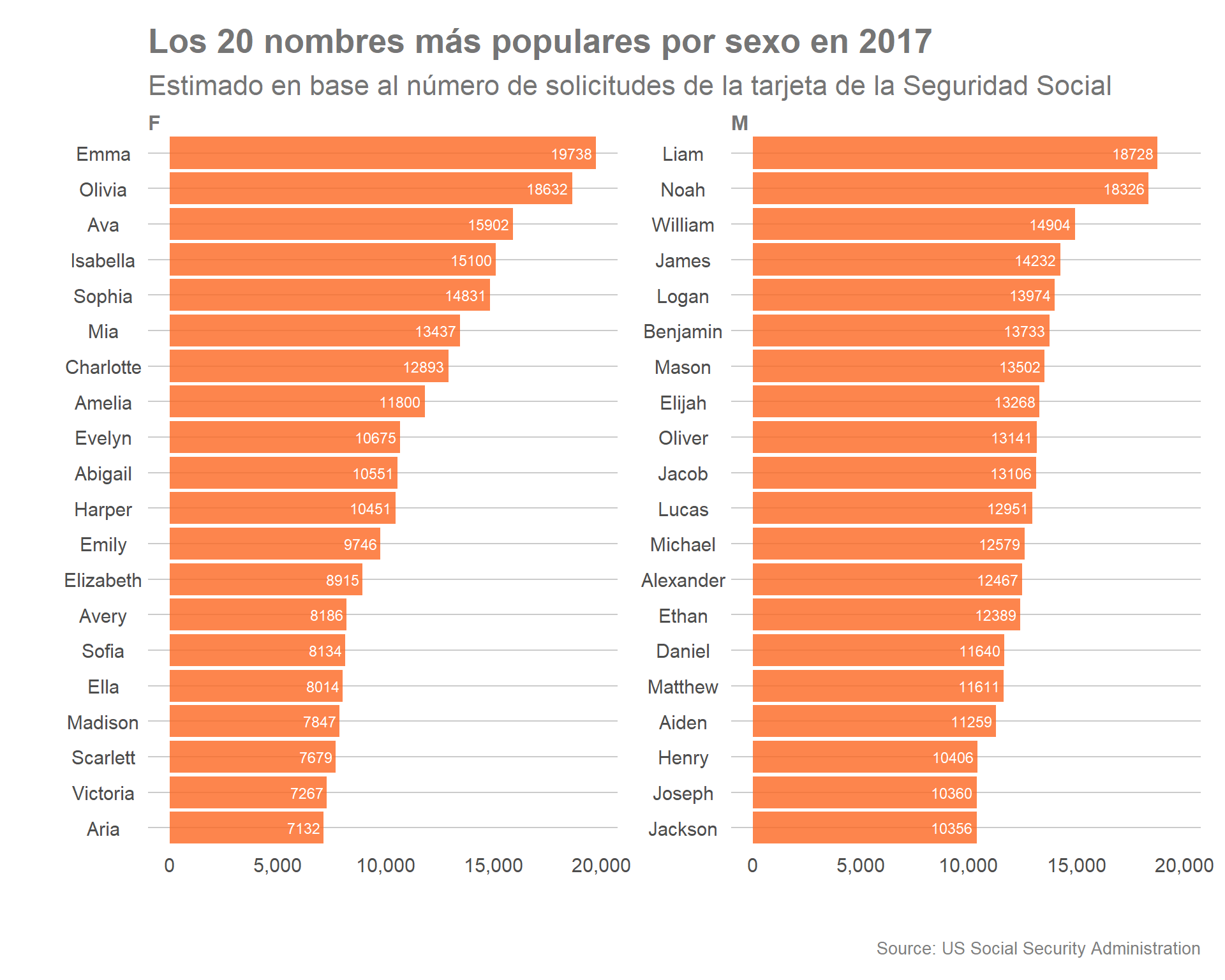
En el caso de que quisiéramos graficar los nombres más populares por sexo en 1880 y 2017 podríamos establecer un código similar al siguiente:
# Creamos un nuevo data frame, con información específica de 1880 y 2017 seleccionando los registros que lideran el ranking.
babynames_2 <- babynames %>%
select(year, sex, name, n) %>%
filter( year == 1880 | year == 2017) %>%
group_by(year, sex, name, n) %>%
arrange (year, sex, n) %>%
group_by( year, sex) %>%
top_n(20, n)
Para realizar los siguientes gráficos vamos a utilizar un theme diseñado por Tradfford Data Lab llamado theme_lab() que particularmente encuentro muy agradable visualmente.
# La descarga de este theme se encuentra en el siguiente link:
source("https://github.com/traffordDataLab/assets/raw/master/theme/ggplot2/theme_lab.R")
Utilizando el data frame creado (babynames_2), identificamos y graficamos para el año 1880 los 40 nombres, 20 de sexo masculino y 20 de sexo femenino, mediante el siguiente código:
babynames_2 %>%
filter( year == 1880) %>%
arrange(desc(n)) %>%
ggplot(aes(reorder(name, n), n)) +
geom_col(fill = "#fc6721",
alpha = 0.8)+
coord_flip() +
facet_wrap(~sex, scales= "free_y", ncol=2)+
theme_lab() +
theme(panel.grid.major.x = element_blank())+
scale_y_continuous(labels = scales::comma) +
geom_text(aes(label=n, y=n + 1),
hjust=1.1,
color="white",
size= 3.2)+
labs(title = "Los 20 nombres más populares por sexo en 1880",
subtitle = "Estimado en base al número de solicitudes de la tarjeta de la Seguridad Social",
caption = "Source: US Social Security Administration",
x = "", y = "",
fill = NULL) 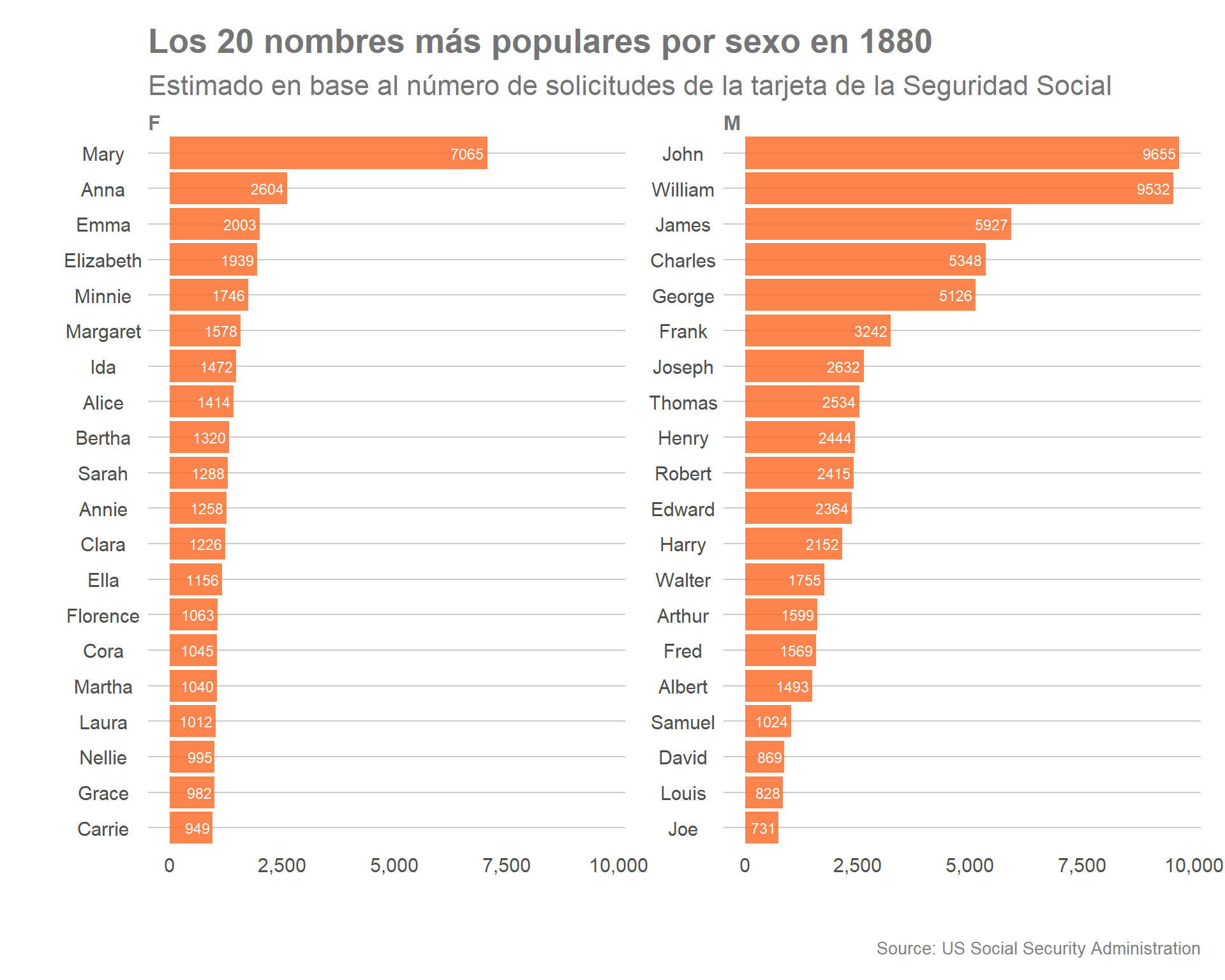
# Como se comprobó previamente Mary y John lideran el ranking en 1880 aunque William, James, Charles o George también fueron nombres de notable popularidad.
De forma similar, modificando un par de líneas del comando anterior podemos realizar el mismo ejercicio para el año 2017, observando de esta forma la evolución de los nombres, y la mayor variedad
babynames_2 %>%
filter( year == 2017) %>%
arrange(desc(n)) %>%
ggplot(aes(reorder(name, n), n)) +
geom_col(fill = "#fc6721",
alpha = 0.8)+
coord_flip() +
facet_wrap(~sex, scales= "free_y", ncol=2)+
theme_lab() +
theme(panel.grid.major.x = element_blank())+
scale_y_continuous(labels = scales::comma) +
geom_text(aes(label=n, y=n + 1),
hjust=1.1,
color="white",
size= 3.2)+
labs(title = "Los 20 nombres más populares por sexo en 2017",
subtitle = "Estimado en base al número de solicitudes de la tarjeta de la Seguridad Social",
caption = "Source: US Social Security Administration",
x = "", y = "",
fill = NULL)