Introducción
Eurostat es la Oficina de Estadística de la Comisión Europea, organismo que se encarga de producir datos, publicar estadísticas e indicadores sobre la Unión Europea promoviendo la armonización de los métodos estadísticos entre los Estados que la conforman. La función de este organismo es fundamental para realizar análisis y comparaciones entre países y entre regiones de la zona euro.
El paquete {eurostat} consiste en un conjunto de herramientas que tiene como finalidad facilitar la descarga de información desde la base de datos de Eurostat. Los autores de este paquete son Leo Lahti, Janne Huovari, Markus Kainu y Przemyslaw Biecek, quienes han puesto a disposición del público información que facilita su utilización y el aprendizaje de sus funcionalidades (véase el artículo en R Journal, el tutorial/ vignette, el cheatsheet del paquete, la documentación sobre sus funcionalidades o el documento de CRAN.r-project ).
La información de la presente entrada difícilmente podrá superar e incluso complementar a la disponible en los enlaces mencionados. No obstante cabe señalar que este post no pretende tener un carácter divulgativo sino que más bien nace con un objetivo de índole personal, en tanto en cuanto espero que sirva principalmente como proceso para familiarizarme con la utilización de dicho paquete. Dicho esto, si este post sirve de apoyo o ayuda a alguna persona interesada en aprender la utilización del paquete {eurostat} pues bienvenido sea.
El paquete eurostat
Como siempre, en primer lugar cargamos los paquetes necesarios. Evidentemente cargamos el paquete {eurostat} y, adicionalmente, cargamos el paquete {tidyverse} cuyas funcionalidades se ajustan muy bien con el paquete {eurostat}.
library(eurostat)
library(tidyverse)
Las funciones disponibles del paquete {eurostat} se pueden encontrar en el link previamente mencionado o indicando la siguiente orden:
library(help= "eurostat")
Para ver el contenido (table of contents - TOC) del paquete podemos utilizar la función get_eurostat_toc(). Esta función nos da como resultado un tibble de 9863 observaciones y 8 variables (esta información se puede consultar en el siguiente archivo de texto). A modo de ejemplo seleccionamos las primeras diez observaciones del dataset.
contenido_eurostat <- get_eurostat_toc()
library(DT)
datatable(contenido_eurostat)
Vemos que el dataset muestra el título o nombre de cada dataset, su código, indica si es folder o table (type), presenta información sobre la fecha de la última actualización u otros cambios o sobre las fechas o periodos que incluye cada dataset.
Ejemplo 1. Homicidios en las principales ciudades europeas
Para buscar información en función de algun patrón o de alguna palabra clave que sirva como pauta podemos utilizar la función search_eurostat(). A modo de ejemplo, y siendo un poco macabros, buscamos las TOC (tablas de contenidos) que estén relacionadas con la palabra homicidio
datatable(search_eurostat("homicide"))
Examinaremos los homicidios intencionados en las grandes ciudades cuyo id es crim_hom_ocit. Para seleccionar y cargar dicho dataset utilizamos la función get_eurostat().
homicidios <- get_eurostat(id="crim_hom_ocit")
head(homicidios)
## # A tibble: 6 x 4
## unit cities time values
## <fct> <fct> <date> <dbl>
## 1 NR AL001C1 2017-01-01 10
## 2 NR BA001C1 2017-01-01 8
## 3 NR BG001C1 2017-01-01 12
## 4 NR CH001C1 2017-01-01 2
## 5 NR CZ001C1 2017-01-01 12
## 6 NR DE001C1 2017-01-01 50
Utilizaremos la orden time_format = "num" dado que la información es anual y, por tanto, resulta más conveniente convertir la fecha a una variable numérica que continuar utilizando una variable date.
homicidios <- get_eurostat(id="crim_hom_ocit", time_format = "num")
head(homicidios)
## # A tibble: 6 x 4
## unit cities time values
## <fct> <fct> <dbl> <dbl>
## 1 NR AL001C1 2017 10
## 2 NR BA001C1 2017 8
## 3 NR BG001C1 2017 12
## 4 NR CH001C1 2017 2
## 5 NR CZ001C1 2017 12
## 6 NR DE001C1 2017 50
Por otro lado, para remplazar los códigos del dataset por etiquetas (labels) usamos la función label_eurostat(). Nótese que, de forma alternativa, al obtener el dataframe con la función get_eurostat() podemos utilizar type= "label" para obtener directamente las variables con etiquetas.
homicidios_labels <- label_eurostat(homicidios)
head(homicidios_labels)
## # A tibble: 6 x 4
## unit cities time values
## <fct> <fct> <dbl> <dbl>
## 1 Number Tiranë 2017 10
## 2 Number Sarajevo 2017 8
## 3 Number Sofia 2017 12
## 4 Number Zürich 2017 2
## 5 Number Praha 2017 12
## 6 Number Berlin 2017 50
str(homicidios_labels)
## tibble [622 x 4] (S3: tbl_df/tbl/data.frame)
## $ unit : Factor w/ 2 levels "Number","Per hundred thousand inhabitants": 1 1 1 1 1 1 1 1 1 1 ...
## $ cities: Factor w/ 39 levels "Tiranë","Sarajevo",..: 1 2 3 4 5 6 7 8 9 10 ...
## $ time : num [1:622] 2017 2017 2017 2017 2017 ...
## $ values: num [1:622] 10 8 12 2 12 50 15 17 35 16 ...
summary(homicidios_labels)
## unit cities
## Number :351 Sofia : 20
## Per hundred thousand inhabitants:271 Madrid : 20
## Helsinki / Helsingfors: 20
## Ljubljana : 20
## Bratislava : 20
## London (greater city) : 20
## (Other) :502
## time values
## Min. :2008 Min. : 0.00
## 1st Qu.:2010 1st Qu.: 1.28
## Median :2012 Median : 4.00
## Mean :2012 Mean : 14.93
## 3rd Qu.:2014 3rd Qu.: 16.00
## Max. :2017 Max. :348.00
##
Vemos que el dataframe, que abarca el periodo 2008-2017, incluye información sobre el número total de homicidios y, por otro lado, sobre número de homicidios por cien mil habitantes.
Para comprobar las etiquetas de las variables y las categorías que se incluyen en el dataset utilizaremos la función label_eurostat_vars() y la función levels().
label_eurostat_vars(names(homicidios_labels))
## [1] "Unit of measure" "Geopolitical entity (declaring)"
## [3] "Period of time"
levels(homicidios_labels$unit)
## [1] "Number" "Per hundred thousand inhabitants"
levels(homicidios_labels$cities)
## [1] "Tiranë" "Sarajevo" "Sofia"
## [4] "Zürich" "Praha" "Berlin"
## [7] "København" "Tallinn" "Athina"
## [10] "Madrid" "Helsinki / Helsingfors" "Paris"
## [13] "Zagreb" "Budapest" "Reykjavík"
## [16] "Roma" "Vilnius" "Riga"
## [19] "Podgorica" "Valletta" "Amsterdam"
## [22] "Oslo" "Warszawa" "Lisboa"
## [25] "Bucuresti" "Beograd" "Ljubljana"
## [28] "Bratislava" "London (greater city)" "Pristinë"
## [31] "Wien" "Lefkosia" "Glasgow City"
## [34] "Belfast" "Bruxelles / Brussel" "Schaan"
## [37] "Luxembourg" "Skopje" "Istanbul"
1. ¿Cuántos Homicidios intencionados por cada 100.000 habitantes se registraron en el año 2008 en las principales ciudades?
A modo de ejemplo supongamos que queremos graficar el número de homicidios por cada cien mil habitantes en el año 2008 en las ciudades seleccionadas por Eurostat. En primer lugar debemos hacer unas pequeñas operaciones sobre el dataframe homicidios_labels que denominaremos homicidios_labels_mil_2008.
homicidios_labels_mil_2008 <- homicidios_labels %>%
filter(unit == "Per hundred thousand inhabitants" & time == "2008" & values > 0.1) %>%
mutate(cities = gsub(cities, pattern = " \\(.*", replacement="")) %>%
mutate(cities = gsub(cities, pattern =" \\/.*", replacement ="")) %>%
arrange(desc(values))
head(homicidios_labels_mil_2008)
## # A tibble: 6 x 4
## unit cities time values
## <fct> <chr> <dbl> <dbl>
## 1 Per hundred thousand inhabitants Vilnius 2008 10.4
## 2 Per hundred thousand inhabitants Tiranë 2008 5.26
## 3 Per hundred thousand inhabitants Riga 2008 4.19
## 4 Per hundred thousand inhabitants Bruxelles 2008 4.12
## 5 Per hundred thousand inhabitants Glasgow City 2008 3.99
## 6 Per hundred thousand inhabitants Podgorica 2008 3.64
Una vez preparado el dataset realizamos un gráfico de barras con {ggplot2}.
ggplot(homicidios_labels_mil_2008, aes(x = reorder(cities, values), y = values)) +
geom_col(color= "white",
fill= "#fc6721",
alpha = 0.8,
size = 2) +
labs(title = "Homicidios intencionados por 100mil habitantes, 2008",
subtitle = "Selección de países",
caption = "Fuente: Eurostat",
y = "", x="") +
coord_flip() +
theme_minimal() +
theme(panel.grid.major.x = element_blank(),
axis.text.y= element_text(size = 12, hjust = 1),
axis.text.x= element_text(size = 10),
plot.title = element_text(size = 15,
face = "bold",
hjust = 0.5),
plot.subtitle = element_text(size=12,
face = "plain",
hjust = 0.5))+
geom_text(aes(label = values, y = values + 0.05),
hjust = 0,
color = "grey40",
size = 2.8)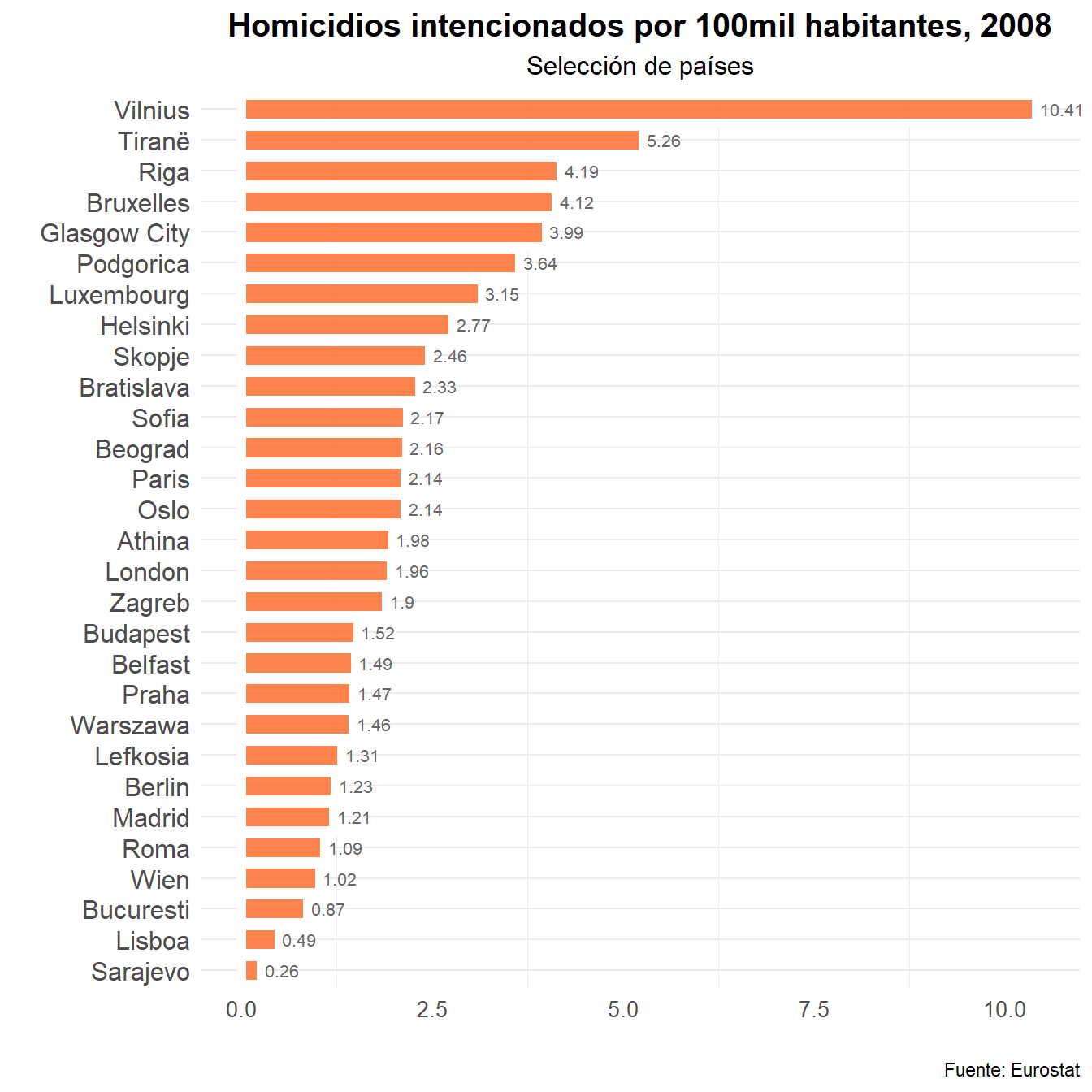
En 2008 Vilnius (Lituania) fue, con diferencia, la ciudad con mayor número de homicidios intencionados por cada 100 mil habitantes de entre las ciudades seleccionadas por Eurostat. Madrid, por su parte, se situaba por debajo de otras grandes ciudades europeas pero se encuentra por encima de Roma, Viena, Bucarest, Lisboa o Sarajevo.
2. ¿Cómo ha evolucionado el número de homicidios intencionados en Madrid, Paris, Londres y Berlín?
Veamos ahora la evolución de los homicidios (por cada 100.000 habitantes) en cuatro de las ciudades presentes en el dataframe: Madrid, Londres, Paris y Berlín. Para ello de nuevo realizamos una serie de operaciones en el dataframe original y generamos el dataset homicidios_MLPB.
homicidios_MLPB <- homicidios_labels %>%
filter(unit == "Per hundred thousand inhabitants") %>%
mutate(cities = gsub(cities, pattern = " \\(.*", replacement="")) %>%
filter(cities == "Madrid" | cities == "London" | cities == "Paris" | cities == "Berlin")
head(homicidios_MLPB)
## # A tibble: 6 x 4
## unit cities time values
## <fct> <chr> <dbl> <dbl>
## 1 Per hundred thousand inhabitants Berlin 2017 1.4
## 2 Per hundred thousand inhabitants Madrid 2017 0.5
## 3 Per hundred thousand inhabitants London 2017 0.07
## 4 Per hundred thousand inhabitants Madrid 2016 0.6
## 5 Per hundred thousand inhabitants London 2016 1.23
## 6 Per hundred thousand inhabitants Berlin 2015 1.21
Y graficamos:
ggplot(homicidios_MLPB, aes(x= time, y= values, shape = cities, color = cities))+
geom_point(size =2) +
geom_line() +
theme_minimal() +
labs(title ="Homicidios intencionados por 100mil habitantes",
subtitle = "Selección de países",
caption = "Fuente: Eurostat",
x= "Year", y = "") 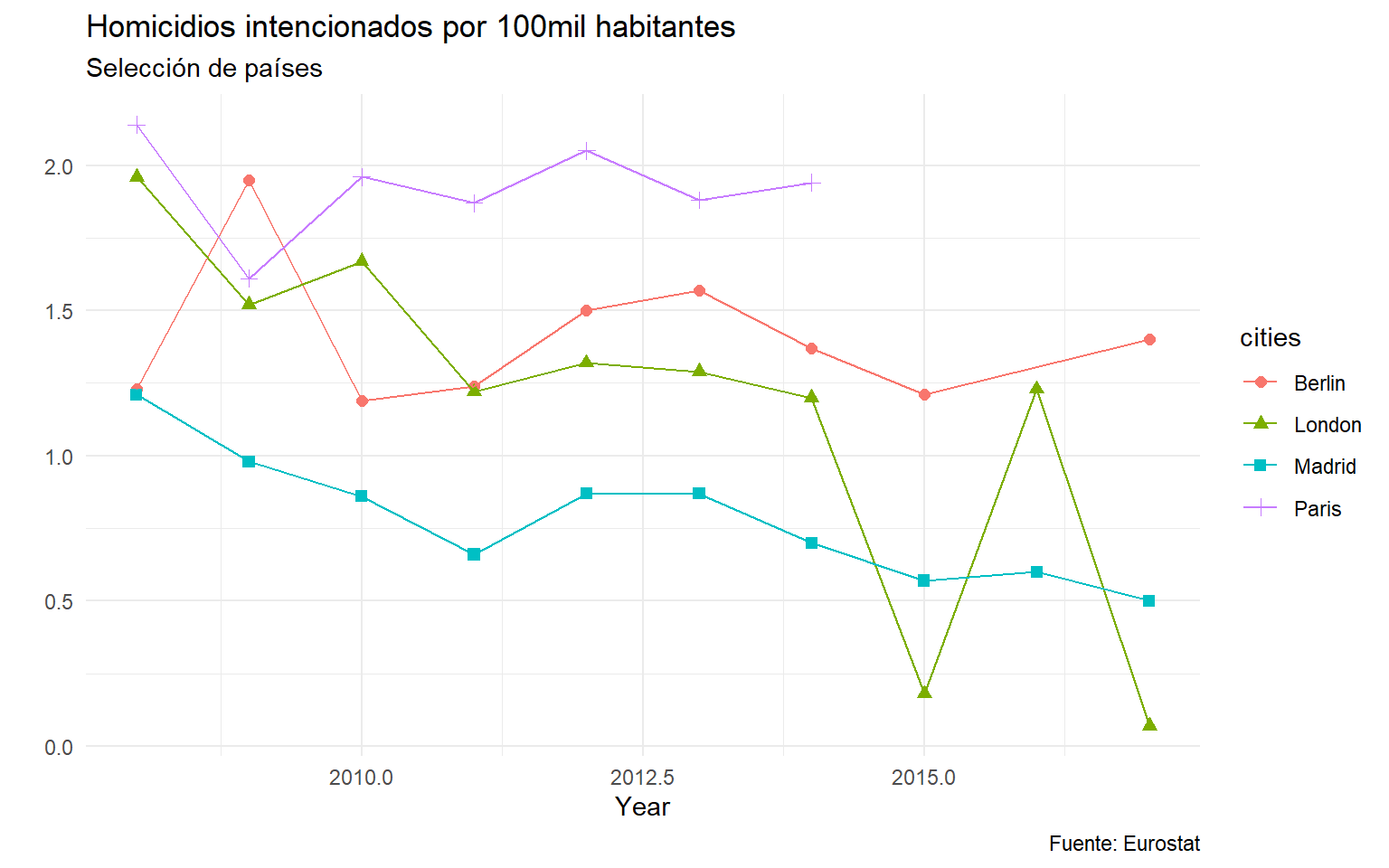
Ejemplo 2. Consumo de alcohol por país
En primer lugar buscamos un dataframe en Eurostat que pueda servirnos para el objetivo marcado que, en este caso, consiste en examinar las diferencias en el consumo de alcohol por país.
datatable(search_eurostat("alcohol consumption"))
Seleccionamos el dataset que lleva como nombre Frequency of alcohol consumption by sex, age and country of citizenship. Al igual que sucedía con el ejemplo previo modificamos el formato para las fechas por su valor numérico dado que los datos del dataset corresponden al año 2014. Para examinar las características del dataframe existen diversas alternativas que podemos utilizar y que no ayudarán a familiarizarnos con la información presente en el dataset.
consumo <- get_eurostat(id="hlth_ehis_al1c", time_format = "num")
head(consumo)
## # A tibble: 6 x 8
## unit frequenc sex age citizen geo time values
## <fct> <fct> <fct> <fct> <fct> <fct> <dbl> <dbl>
## 1 PC DAY F TOTAL EU28_FOR EU27_2020 2014 6.3
## 2 PC DAY F TOTAL FOR EU27_2020 2014 4.8
## 3 PC DAY F TOTAL NAT EU27_2020 2014 4.9
## 4 PC DAY F TOTAL NEU28_FOR EU27_2020 2014 3.5
## 5 PC DAY F Y15-24 EU28_FOR EU27_2020 2014 0
## 6 PC DAY F Y15-24 FOR EU27_2020 2014 0
consumo_labels <- label_eurostat(consumo)
head(consumo_labels)
## # A tibble: 6 x 8
## unit frequenc sex age citizen geo time values
## <fct> <fct> <fct> <fct> <fct> <fct> <dbl> <dbl>
## 1 Percen~ Every day Femal~ Total EU28 countries (~ European Uni~ 2014 6.3
## 2 Percen~ Every day Femal~ Total Foreign country European Uni~ 2014 4.8
## 3 Percen~ Every day Femal~ Total Reporting country European Uni~ 2014 4.9
## 4 Percen~ Every day Femal~ Total Non-EU28 countri~ European Uni~ 2014 3.5
## 5 Percen~ Every day Femal~ From 15~ EU28 countries (~ European Uni~ 2014 0
## 6 Percen~ Every day Femal~ From 15~ Foreign country European Uni~ 2014 0
str(consumo_labels)
## tibble [44,268 x 8] (S3: tbl_df/tbl/data.frame)
## $ unit : Factor w/ 1 level "Percentage": 1 1 1 1 1 1 1 1 1 1 ...
## $ frequenc: Factor w/ 7 levels "Every day","Less than once a month",..: 1 1 1 1 1 1 1 1 1 1 ...
## $ sex : Factor w/ 3 levels "Females","Males",..: 1 1 1 1 1 1 1 1 1 1 ...
## $ age : Factor w/ 17 levels "Total","From 15 to 24 years",..: 1 1 1 1 2 2 2 2 3 3 ...
## $ citizen : Factor w/ 4 levels "EU28 countries (2013-2020) except reporting country",..: 1 2 3 4 1 2 3 4 1 2 ...
## $ geo : Factor w/ 31 levels "European Union - 27 countries (from 2020)",..: 1 1 1 1 1 1 1 1 1 1 ...
## $ time : num [1:44268] 2014 2014 2014 2014 2014 ...
## $ values : num [1:44268] 6.3 4.8 4.9 3.5 0 0 0.2 0 0.3 0.5 ...
summary(consumo_labels)
## unit frequenc sex
## Percentage:44268 Every day :6324 Females:14756
## Less than once a month :6324 Males :14756
## Every month :6324 Total :14756
## Not in the last 12 months :6324
## Never :6324
## Never or not in the last 12 months:6324
## Every week :6324
## age
## Total : 2604
## From 15 to 24 years: 2604
## From 15 to 29 years: 2604
## From 15 to 64 years: 2604
## From 18 to 24 years: 2604
## From 18 to 44 years: 2604
## (Other) :28644
## citizen
## EU28 countries (2013-2020) except reporting country :11067
## Foreign country :11067
## Reporting country :11067
## Non-EU28 countries (2013-2020) nor reporting country:11067
##
##
##
## geo time
## European Union - 27 countries (from 2020): 1428 Min. :2014
## European Union - 28 countries (2013-2020): 1428 1st Qu.:2014
## Belgium : 1428 Median :2014
## Bulgaria : 1428 Mean :2014
## Czechia : 1428 3rd Qu.:2014
## Denmark : 1428 Max. :2014
## (Other) :35700
## values
## Min. : 0.00
## 1st Qu.: 4.80
## Median :13.50
## Mean :16.75
## 3rd Qu.:25.30
## Max. :99.50
## NA's :13545
El dataframe contiene información del consumo según frecuencia (cada día, menos de una vez al mes, etc.), de sexo (femenino, masculino o total), por rangos de edad, por ciudadanía y por país. Para consultar el nombre completo de las variables del data set podemos utilizar la función label_eurostat_vars(names()) y para comprobar las distintas categorías de las observaciones podemos examinar los levels como se expone a continuación. De esta forma podemos tener una imagen más adecuada del dataset sobre el que estamos trabajando:
label_eurostat_vars(names(consumo_labels))
## [1] "Unit of measure" "Frequency"
## [3] "Sex" "Age class"
## [5] "Country of citizenship" "Geopolitical entity (reporting)"
## [7] "Period of time"
levels(consumo_labels$unit)
## [1] "Percentage"
levels(consumo_labels$frequenc)
## [1] "Every day" "Less than once a month"
## [3] "Every month" "Not in the last 12 months"
## [5] "Never" "Never or not in the last 12 months"
## [7] "Every week"
levels(consumo_labels$sex)
## [1] "Females" "Males" "Total"
levels(consumo_labels$age)
## [1] "Total" "From 15 to 24 years" "From 15 to 29 years"
## [4] "From 15 to 64 years" "From 18 to 24 years" "From 18 to 44 years"
## [7] "From 18 to 64 years" "From 25 to 34 years" "From 25 to 64 years"
## [10] "From 35 to 44 years" "From 45 to 54 years" "From 45 to 64 years"
## [13] "From 55 to 64 years" "From 65 to 74 years" "18 years or over"
## [16] "65 years or over" "75 years or over"
levels(consumo_labels$citizen)
## [1] "EU28 countries (2013-2020) except reporting country"
## [2] "Foreign country"
## [3] "Reporting country"
## [4] "Non-EU28 countries (2013-2020) nor reporting country"
levels(consumo_labels$geo)
## [1] "European Union - 27 countries (from 2020)"
## [2] "European Union - 28 countries (2013-2020)"
## [3] "Belgium"
## [4] "Bulgaria"
## [5] "Czechia"
## [6] "Denmark"
## [7] "Germany (until 1990 former territory of the FRG)"
## [8] "Estonia"
## [9] "Ireland"
## [10] "Greece"
## [11] "Spain"
## [12] "Croatia"
## [13] "Italy"
## [14] "Cyprus"
## [15] "Latvia"
## [16] "Lithuania"
## [17] "Luxembourg"
## [18] "Hungary"
## [19] "Malta"
## [20] "Austria"
## [21] "Poland"
## [22] "Portugal"
## [23] "Romania"
## [24] "Slovenia"
## [25] "Slovakia"
## [26] "Finland"
## [27] "Sweden"
## [28] "United Kingdom"
## [29] "Iceland"
## [30] "Norway"
## [31] "Turkey"
levels(consumo$geo)
## [1] "EU27_2020" "EU28" "BE" "BG" "CZ" "DK"
## [7] "DE" "EE" "IE" "EL" "ES" "HR"
## [13] "IT" "CY" "LV" "LT" "LU" "HU"
## [19] "MT" "AT" "PL" "PT" "RO" "SI"
## [25] "SK" "FI" "SE" "UK" "IS" "NO"
## [31] "TR"
Resulta curioso comprobar que el dataset seleccionado, obtenido de Eurostat, no contiene información sobre Francia.
Partiendo del dataset obtenido de Eurostat vamos a intentar responder algunas preguntas:
1. ¿Cuál es la proporción de personas por país que consumen alcohol de forma diaria?
Tal y como hemos hecho previamente, en primer lugar realizamos una serie de operaciones donde seleccionamos la frecuencia (every day), elegimos ambos sexos y cualquier edad. Queremos de esta forma mostrar el consumo de alcohol en términos generales y agregados.
consumo <- get_eurostat(id="hlth_ehis_al1c", time_format = "num")
consumo_total <- consumo %>%
filter(frequenc == "DAY") %>%
filter(sex == "T") %>%
filter(age == "TOTAL") %>%
filter(citizen == "NAT") %>%
filter(geo != "EU28" & geo !="EU27_2020")
head(consumo_total)
## # A tibble: 6 x 8
## unit frequenc sex age citizen geo time values
## <fct> <fct> <fct> <fct> <fct> <fct> <dbl> <dbl>
## 1 PC DAY T TOTAL NAT BE 2014 14.5
## 2 PC DAY T TOTAL NAT BG 2014 8.8
## 3 PC DAY T TOTAL NAT CZ 2014 9.5
## 4 PC DAY T TOTAL NAT DK 2014 11.6
## 5 PC DAY T TOTAL NAT DE 2014 9.2
## 6 PC DAY T TOTAL NAT EE 2014 2.1
Realizamos el mapa utilizando la función get_eurostat_geospatial(), estableciendo 8 rangos para los valores y utilizando como paleta de colores la llamada Spectral.
consumo_total_mapa <- get_eurostat_geospatial(nuts_level = 0) %>%
right_join(consumo_total) %>%
mutate(categorias = cut_to_classes(values, n=8, decimals=1))
head(select(consumo_total_mapa, geo, values, categorias), 3)
## Simple feature collection with 3 features and 3 fields
## geometry type: MULTIPOLYGON
## dimension: XY
## bbox: xmin: 12.10024 ymin: 34.56908 xmax: 34.56859 ymax: 51.0547
## geographic CRS: WGS 84
## geo values categorias geometry
## 1 BG 8.8 6.5 ~< 9.5 MULTIPOLYGON (((22.99717 43...
## 2 CY 4.1 3.5 ~< 6.5 MULTIPOLYGON (((33.75237 34...
## 3 CZ 9.5 9.5 ~< 12.4 MULTIPOLYGON (((14.49122 51...
ggplot(consumo_total_mapa, aes(fill=categorias)) +
geom_sf(color = alpha("white", 1/2), alpha= 0.9) +
xlim(c(-20, 44)) +
ylim(c(35, 70)) +
labs(title = "Frequency of alcohol consumption, 2014",
subtitle = "Citizenship: National (has the citizenship of the reporting country)",
caption = "Source: Eurostat",
fill= "%")+
theme_minimal() +
theme(
axis.line = element_blank(),
axis.text = element_blank(),
axis.title = element_blank(),
axis.ticks = element_blank(),
plot.background = element_rect(fill = "snow", color = NA),
panel.background = element_rect(fill= "snow", color = NA),
plot.title = element_text(size = 16, hjust = 0.5),
plot.subtitle = element_text(size = 10, hjust = 0.5),
plot.caption = element_text(size = 8, hjust = 1),
legend.title = element_text(color = "grey40", size = 8),
legend.text = element_text(color = "grey40", size = 7, hjust = 0),
legend.position = c(0.93, 0.6),
plot.margin = unit(c(0.5,2,0.5,1), "cm")) +
scale_fill_brewer(palette= "Spectral")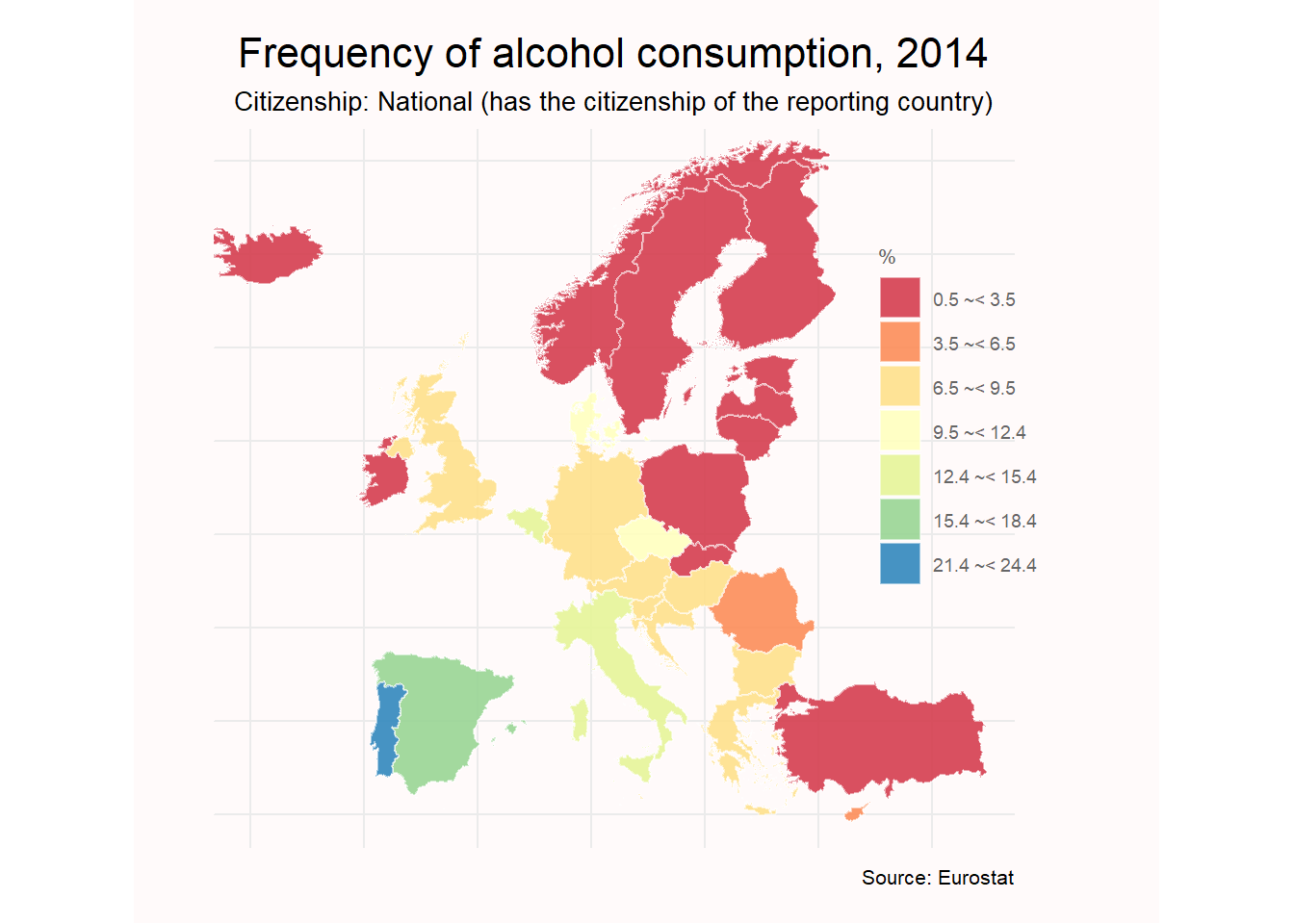
2. ¿Cuál es la proporción de mujeres por país que consumen alcohol de forma diaria?
En este caso vamos a analizar únicamente la población femenina. Para ello realizamos una pequeña modificación en el dataframe indicando: filter(sex == "F").
consumo <- get_eurostat(id="hlth_ehis_al1c", time_format = "num")
consumo_F <- consumo %>%
filter(frequenc == "DAY") %>%
filter(sex == "F") %>%
filter(age == "TOTAL") %>%
filter(citizen == "NAT") %>%
filter(geo != "EU28"& geo !="EU27_2020")
Graficamos:
consumo_F_mapa <- get_eurostat_geospatial(nuts_level = 0) %>%
right_join(consumo_F) %>%
mutate(categorias = cut_to_classes(values, n=10, decimals=1))
head(select(consumo_F_mapa, geo, values, categorias), 3)
## Simple feature collection with 3 features and 3 fields
## geometry type: MULTIPOLYGON
## dimension: XY
## bbox: xmin: 12.10024 ymin: 34.56908 xmax: 34.56859 ymax: 51.0547
## geographic CRS: WGS 84
## geo values categorias geometry
## 1 BG 3.6 2.5 ~< 3.6 MULTIPOLYGON (((22.99717 43...
## 2 CY 0.7 0.1 ~< 1.3 MULTIPOLYGON (((33.75237 34...
## 3 CZ 3.2 2.5 ~< 3.6 MULTIPOLYGON (((14.49122 51...
ggplot(consumo_F_mapa, aes(fill=categorias)) +
geom_sf(color = alpha("white", 1/2), alpha= 0.9) +
xlim(c(-20, 44)) +
ylim(c(35, 70)) +
labs(title = "Frequency of female alcohol consumption, 2014",
subtitle = "Citizenship: National (has the citizenship of the reporting country)",
caption = "Source: Eurostat",
fill= "%")+
theme_minimal() +
theme(
axis.line = element_blank(),
axis.text = element_blank(),
axis.title = element_blank(),
axis.ticks = element_blank(),
plot.background = element_rect(fill = "snow", color = NA),
panel.background = element_rect(fill= "snow", color = NA),
plot.title = element_text(size = 16, hjust = 0.5),
plot.subtitle = element_text(size = 10, hjust = 0.5),
plot.caption = element_text(size = 8, hjust = 1),
legend.title = element_text(color = "grey40", size = 8),
legend.text = element_text(color = "grey40", size = 7, hjust = 0),
legend.position = c(0.93, 0.6),
plot.margin = unit(c(0.5,2,0.5,1), "cm")) +
scale_fill_brewer(palette= "Spectral")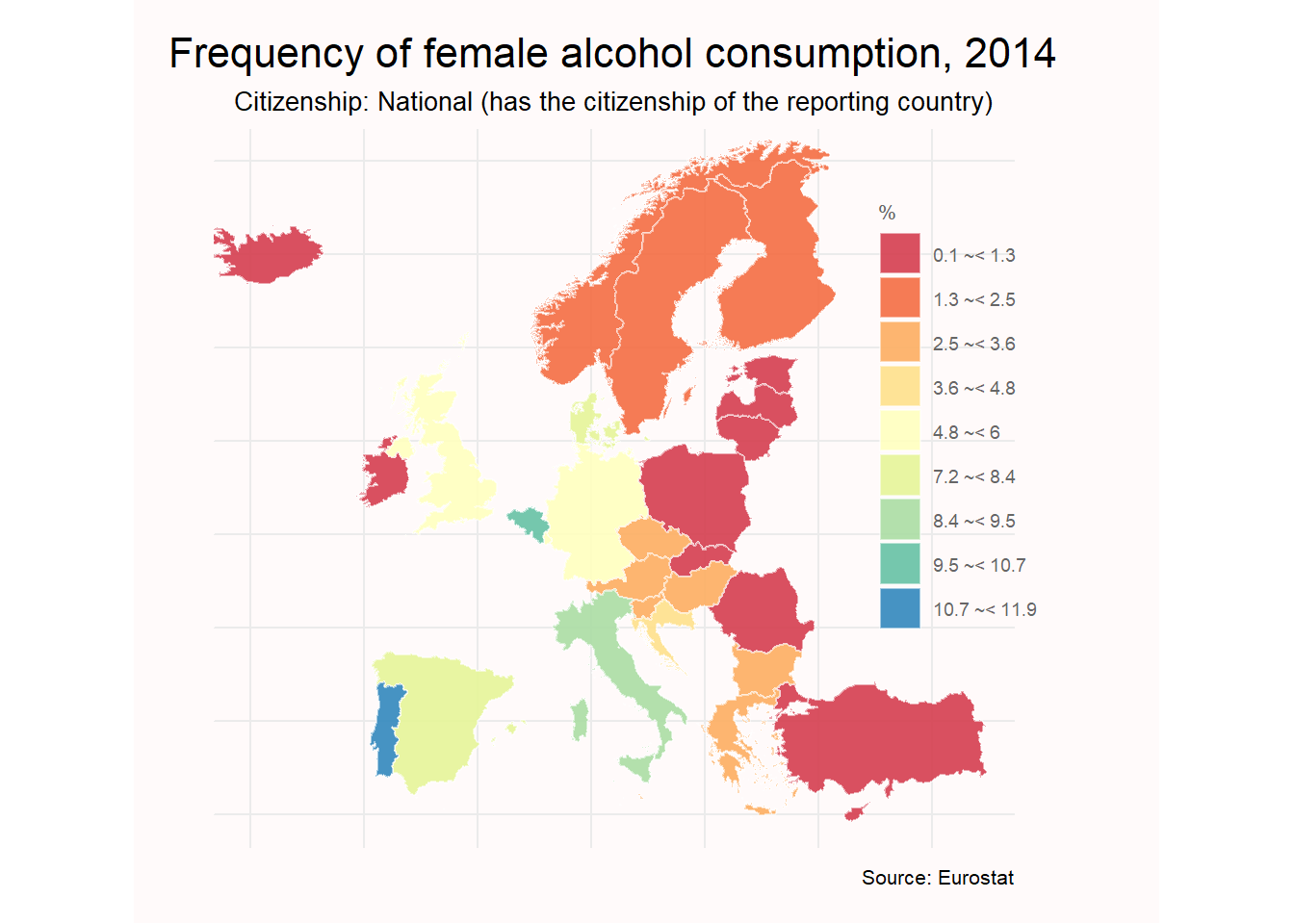
3. ¿Cuál es la proporción de hombres por país que consumen alcohol de forma diaria?
Para ser equitativos, y por curiosidad personal, comprobamos el consumo de alcohol de la población masculina. Para ello indicamos: `filter(sex == “M”).
consumo <- get_eurostat(id="hlth_ehis_al1c", time_format = "num")
consumo_M <- consumo %>%
filter(frequenc == "DAY") %>%
filter(sex == "M") %>%
filter(age == "TOTAL") %>%
filter(citizen == "NAT") %>%
filter(geo != "EU28" & geo !="EU27_2020")
Y graficamos:
consumo_M_mapa <- get_eurostat_geospatial(nuts_level = 0) %>%
right_join(consumo_M) %>%
mutate(categorias = cut_to_classes(values, n=10, decimals=1))
head(select(consumo_M_mapa, geo, values, categorias), 3)
## Simple feature collection with 3 features and 3 fields
## geometry type: MULTIPOLYGON
## dimension: XY
## bbox: xmin: 12.10024 ymin: 34.56908 xmax: 34.56859 ymax: 51.0547
## geographic CRS: WGS 84
## geo values categorias geometry
## 1 BG 14.8 12.1 ~< 15.9 MULTIPOLYGON (((22.99717 43...
## 2 CY 7.6 4.6 ~< 8.4 MULTIPOLYGON (((33.75237 34...
## 3 CZ 16.3 15.9 ~< 19.7 MULTIPOLYGON (((14.49122 51...
ggplot(consumo_M_mapa, aes(fill=categorias)) +
geom_sf(color = alpha("white", 1/2), alpha= 0.9) +
xlim(c(-20, 44)) +
ylim(c(35, 70)) +
labs(title = "Frequency of male alcohol consumption, 2014",
subtitle = "Citizenship: National (has the citizenship of the reporting country)",
caption = "Source: Eurostat",
fill= "%")+
theme_minimal() +
theme(
axis.line = element_blank(),
axis.text = element_blank(),
axis.title = element_blank(),
axis.ticks = element_blank(),
plot.background = element_rect(fill = "snow", color = NA),
panel.background = element_rect(fill= "snow", color = NA),
plot.title = element_text(size = 16, hjust = 0.5),
plot.subtitle = element_text(size = 10, hjust = 0.5),
plot.caption = element_text(size = 8, hjust = 1),
legend.title = element_text(color = "grey40", size = 8),
legend.text = element_text(color = "grey40", size = 7, hjust = 0),
legend.position = c(0.93, 0.6),
plot.margin = unit(c(0.5,2,0.5,1), "cm")) +
scale_fill_brewer(palette= "Spectral")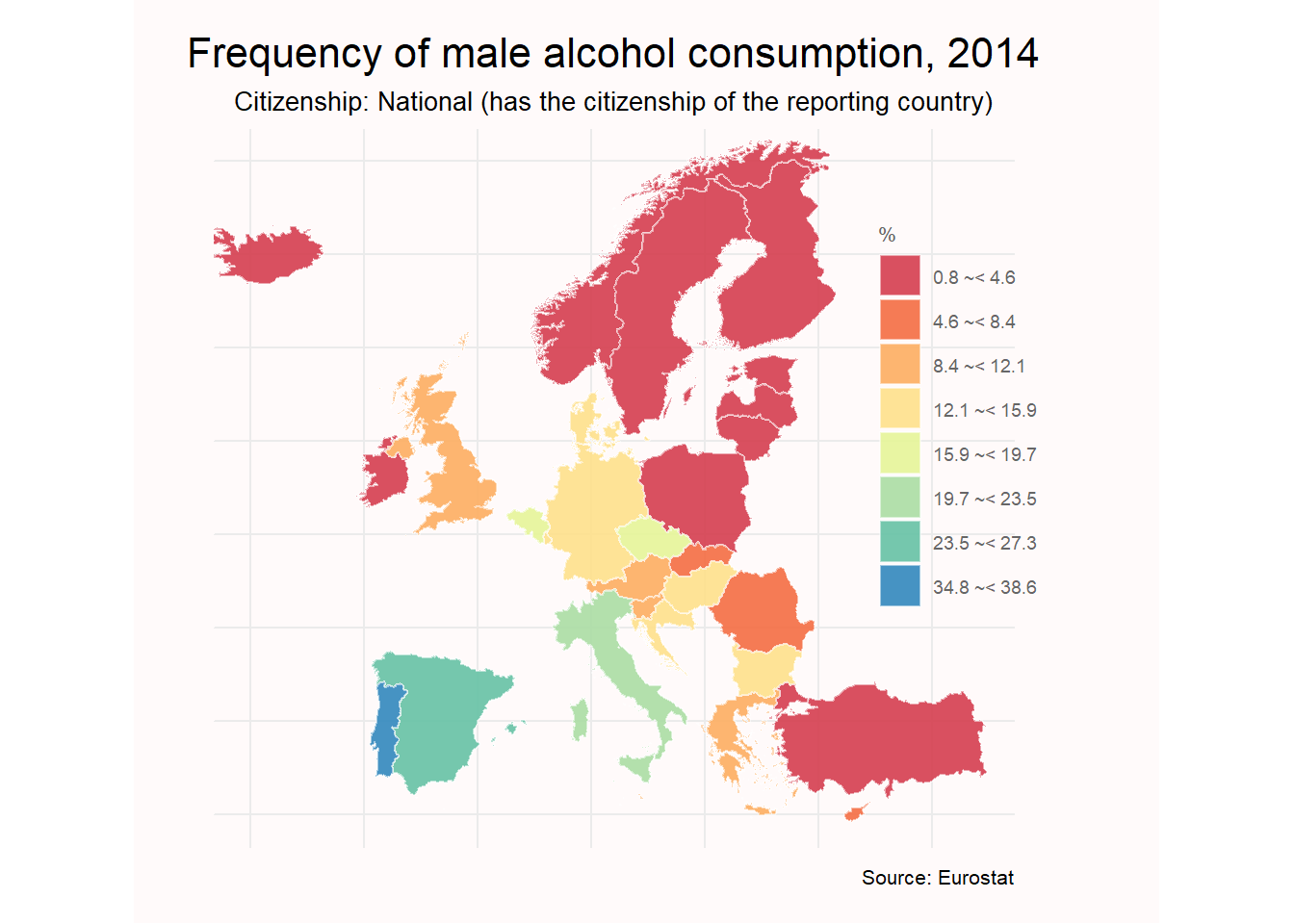
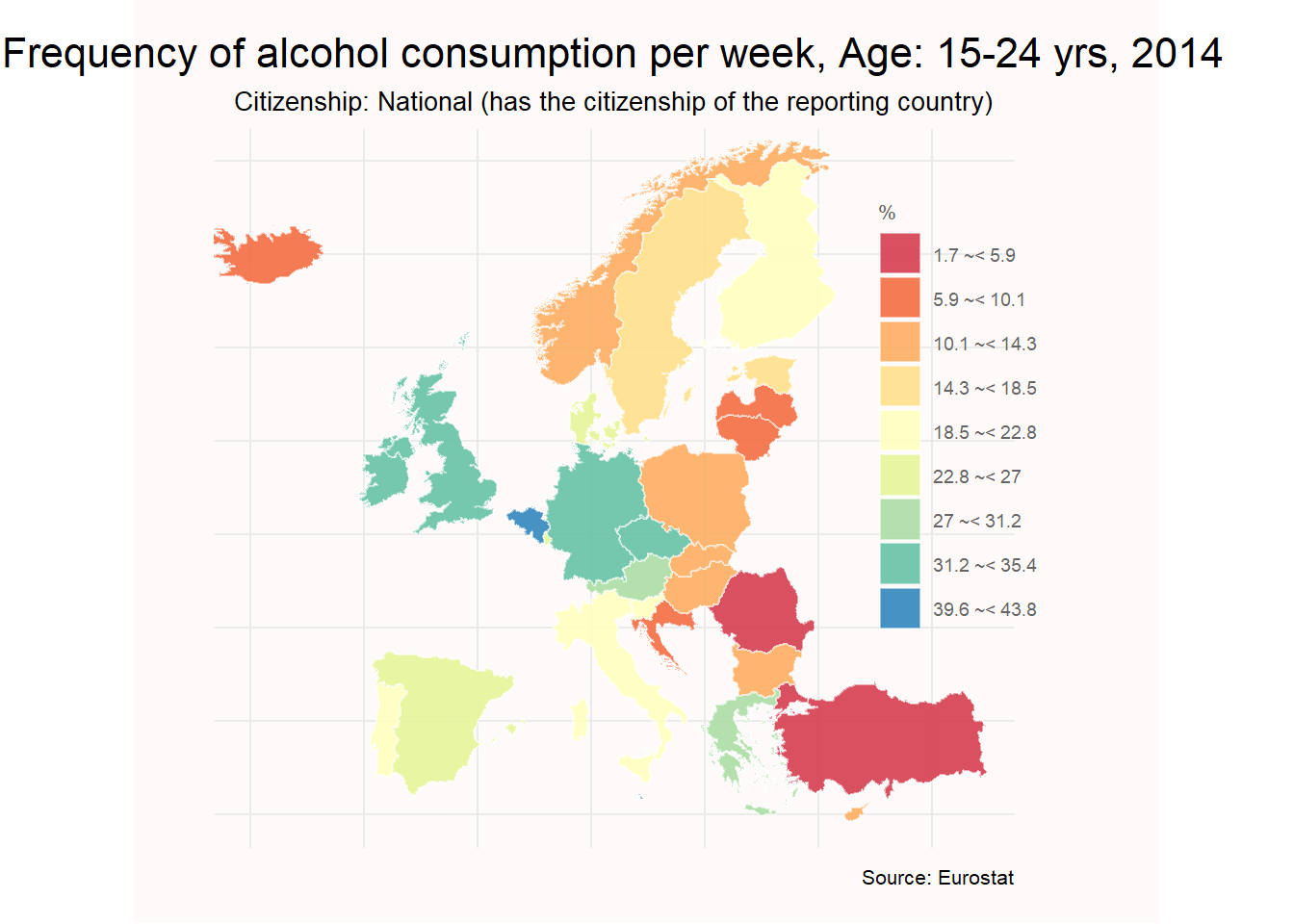
4. ¿Cuál es la proporción de población de entre 15 y 24 años por país que consumen alcohol cada semana?
Por último examinamos la población, pero en esta ocasión seleccionamos la población con una edad comprendida entre los 15 y los 24 años, que consumen alcohol cada semana. Para ello realizamos los cambios necesarios como se indica a continuación
consumo <- get_eurostat(id="hlth_ehis_al1c", time_format = "num")
consumo_1524 <- consumo %>%
filter(frequenc == "WEEK") %>%
filter(sex == "T") %>%
filter(age == "Y15-24") %>%
filter(citizen == "NAT") %>%
filter(geo != "EU28"& geo != "EU27_2020")
Y realizamos el gráfico:
consumo_1524_mapa <- get_eurostat_geospatial(nuts_level = 0) %>%
right_join(consumo_1524) %>%
mutate(categorias = cut_to_classes(values, n=10, decimals=1))
head(select(consumo_1524_mapa, geo, values, categorias), 3)
## Simple feature collection with 3 features and 3 fields
## geometry type: MULTIPOLYGON
## dimension: XY
## bbox: xmin: 12.10024 ymin: 34.56908 xmax: 34.56859 ymax: 51.0547
## geographic CRS: WGS 84
## geo values categorias geometry
## 1 BG 11.6 10.1 ~< 14.3 MULTIPOLYGON (((22.99717 43...
## 2 CY 13.3 10.1 ~< 14.3 MULTIPOLYGON (((33.75237 34...
## 3 CZ 33.7 31.2 ~< 35.4 MULTIPOLYGON (((14.49122 51...
ggplot(consumo_1524_mapa, aes(fill=categorias)) +
geom_sf(color = alpha("white", 1/2), alpha= 0.9) +
xlim(c(-20, 44)) +
ylim(c(35, 70)) +
labs(title = "Frequency of alcohol consumption per week, Age: 15-24 yrs, 2014",
subtitle = "Citizenship: National (has the citizenship of the reporting country)",
caption = "Source: Eurostat",
fill= "%")+
theme_minimal() +
theme(
axis.line = element_blank(),
axis.text = element_blank(),
axis.title = element_blank(),
axis.ticks = element_blank(),
plot.background = element_rect(fill = "snow", color = NA),
panel.background = element_rect(fill= "snow", color = NA),
plot.title = element_text(size = 16, hjust = 0.5),
plot.subtitle = element_text(size = 10, hjust = 0.5),
plot.caption = element_text(size = 8, hjust = 1),
legend.title = element_text(color = "grey40", size = 8),
legend.text = element_text(color = "grey40", size = 7, hjust = 0),
legend.position = c(0.93, 0.6),
plot.margin = unit(c(0.5,2,0.5,1), "cm")) +
scale_fill_brewer(palette= "Spectral")