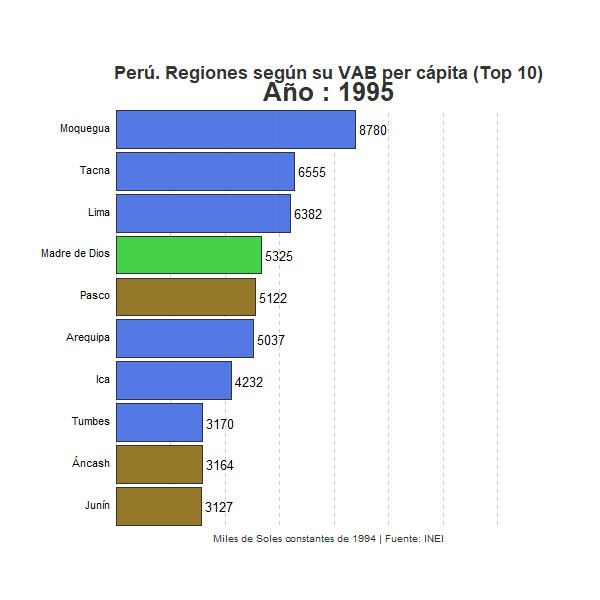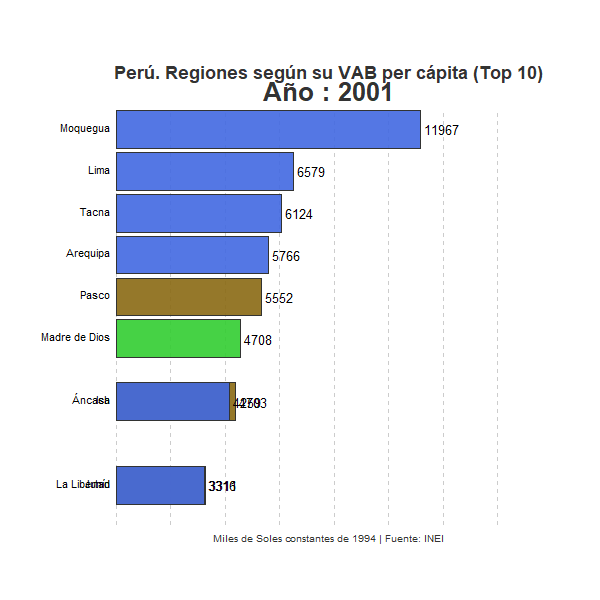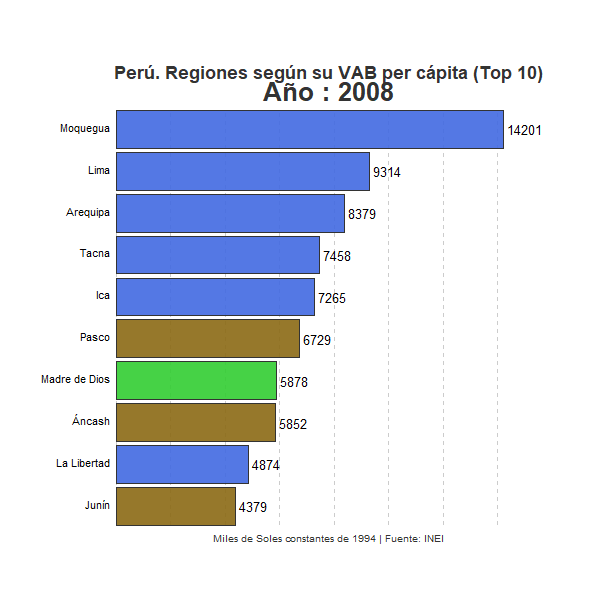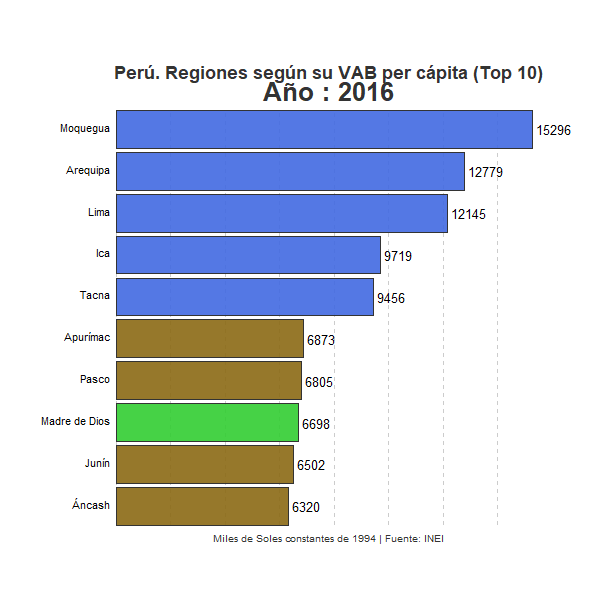Gráfico animado del VAB
Últimamente se ha hecho bastante popular en las redes sociales un gráfico animado (denominados bar chart race) donde se muestra la evolución del ranking de distintas economías, generalmente países, según su PIB o su PIB por habitante. En estos gráficos, generalmente gráficos de barras, se va observando para cada año que países ocupan los primeros puestos en el ranking y cómo han ido evolucionando a lo largo del tiempo. Suele sorprender el rápido avance que ha registrado China, país que ha sufrido grandes transformaciones económicas y sociales en las últimas décadas.
En este post vamos a mostrar cómo realizar un gráfico de estas carcterísticas. En esta ocasión vamos a mostrar la evolución del ranking de regiones peruanas según su VAB per cápita para el periodo 1996-2016. Perú está dividido en 24 regiones y una Provincia Constitucional que es El Callao (en esta ocasión Lima y El Callao se contabilizan conjuntamente). Las series históricas, que deflactamos previamente para obtener una sóla coherente para todo el periodo en miles de Soles constantes de 1994, la obtenemos del Instituto Nacional de Estadística e Informática del Perú (INEI).
Preparación del dataset
En primer lugar descargamos los siguientes paquetes en nuestra sesión:
library(readxl)
library(tidyverse)
library(gganimate)
Cargamos el dataset con read_excel() y observamos los datos, previamente deflactados, de las regiones peruanas obtenidos del INEI para el periodo de tiempo 1995-2016. Las primeras diez observaciones del dataset las podemos seleccionar con la función head()
Peru <- read_excel("./datasets/Peru_vabpc_95_16.xlsx")
head(Peru, n = 10)
## # A tibble: 10 x 24
## Nombre Area `1995` `1996` `1997` `1998` `1999` `2000` `2001` `2002` `2003`
## <chr> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 Amazo~ Selva 1680. 1853. 1824. 1924. 1840. 1863. 1835. 1910. 1996.
## 2 Áncash Sier~ 3164. 3361. 3294. 3022. 3604. 3638. 4037. 4703. 4772.
## 3 Apurí~ Sier~ 1349. 1413. 1447. 1355. 1436. 1397. 1216. 1278. 1334.
## 4 Arequ~ Costa 5037. 5019. 5298. 5202. 5191. 5283. 5387. 5766. 5895.
## 5 Ayacu~ Sier~ 1648. 1681. 1763. 1789. 1801. 1810. 1788. 1870. 1942.
## 6 Cajam~ Sier~ 1922. 1938. 2151. 2335. 2469. 2547. 2493. 2731. 2947.
## 7 Cusco Sier~ 2175. 2172. 2310. 2308. 2234. 2253. 2194. 2086. 2195.
## 8 Huanc~ Sier~ 2602. 2760. 2929. 2938. 2940. 2793. 2700. 2632. 2683.
## 9 Huánu~ Sier~ 1671. 1727. 1795. 1726. 1730. 1755. 1678. 1694. 1833.
## 10 Ica Costa 4232. 4114. 4387. 4050. 4125. 4218. 4055. 4259. 4343.
## # ... with 13 more variables: `2004` <dbl>, `2005` <dbl>, `2006` <dbl>,
## # `2007` <dbl>, `2008` <dbl>, `2009` <dbl>, `2010` <dbl>, `2011` <dbl>,
## # `2012` <dbl>, `2013` <dbl>, `2014` <dbl>, `2015` <dbl>, `2016` <dbl>
Para transformar el formato ancho a un formato largo, más apropiado para su manejo, podemos utilizar la función gather() como se indica a continuación. El resultado serán cuatro columnas, una donde se indicará el nombre de la región, una segunda columna que indicará si la región es de Sierra, Selva o Costa (clasificación que suele utilizarse en Perú para clasificar las regiones aunque existen otras que seleccionan las regiones en un mayor número de subcategorías), una tercera columna que indicará el año que representa cada observacion y una última columna que indicará el valor del Valor Agregado Bruto por habitante para cada región en cada uno de los años del periodo.
Peru <- Peru %>%
gather(key= "year", value= "vabpc", 3:24 )
head(Peru)
## # A tibble: 6 x 4
## Nombre Area year vabpc
## <chr> <chr> <chr> <dbl>
## 1 Amazonas Selva 1995 1680.
## 2 Áncash Sierra 1995 3164.
## 3 Apurímac Sierra 1995 1349.
## 4 Arequipa Costa 1995 5037.
## 5 Ayacucho Sierra 1995 1648.
## 6 Cajamarca Sierra 1995 1922.
Como el objetivo es realizar un gráfico que muestre el ranking de regiones por cada año según su VAB por habitante lo primero que debemos realizar es identificar el puesto ocupa cada región para cada año según dicho indicador. Para ello utilizamos la función rank() de la siguiente forma:
Peru_rangos <- Peru %>%
group_by(year) %>%
mutate(rango = rank(-vabpc),
labels = paste0(" ", round(vabpc)))
Si ordenamos nuestro nuevo data set por año y rango con la función arrange() del paquete tidyverse podemos observar el resultado del ranking realizado. Se comprueba que para el año inicial, 1995, la región de Moquegua, una región costera pequeña situada en el sur del país, lidera el ranking seguido por las regiones de Tacna (costa), Lima (costa), Madre de Dios (selva) y Pasco (sierra). Esta clasificación se ha realizado para cada uno de los años del periodo.
Peru_rangos %>%
arrange(year, rango)
## # A tibble: 528 x 6
## # Groups: year [22]
## Nombre Area year vabpc rango labels
## <chr> <chr> <chr> <dbl> <dbl> <chr>
## 1 Moquegua Costa 1995 8780. 1 " 8780"
## 2 Tacna Costa 1995 6555. 2 " 6555"
## 3 Lima Costa 1995 6382. 3 " 6382"
## 4 Madre de Dios Selva 1995 5325. 4 " 5325"
## 5 Pasco Sierra 1995 5122. 5 " 5122"
## 6 Arequipa Costa 1995 5037. 6 " 5037"
## 7 Ica Costa 1995 4232. 7 " 4232"
## 8 Tumbes Costa 1995 3170. 8 " 3170"
## 9 Áncash Sierra 1995 3164. 9 " 3164"
## 10 Junín Sierra 1995 3127. 10 " 3127"
## # ... with 518 more rows
Gráfico animado con gganimate
Una vez hemos preparado el dataset procedemos a realizar el gráfico animado. Llamaremos al gráfico plot_peru y lo guardamos con dicho nombre. Utilizaremos el color azul para identificar las regiones mayoritariamente costeras, el color verde las regiones selváticas y el color marrón indicará las regiones cuyo territorio es mayoritariamente de sierra o montañoso. El nombre de los colores utilizados, seleccionados con la función scale_fill_manual() se han obtenido del siguiente link: http://www.stat.columbia.edu/~tzheng/files/Rcolor.pdf
plot_peru <- ggplot(Peru_rangos, aes(rango, group = Nombre,
fill = Area)) +
geom_col(aes(y = vabpc), alpha = 0.9, color = "white") +
coord_flip(clip = "off", expand = FALSE) +
geom_text(aes(y = 0, label = paste(Nombre, " ")), vjust = 0.2, hjust = 1) +
geom_text(aes(y= vabpc, label = labels, hjust = 0)) +
scale_y_continuous(labels = scales::comma) +
scale_x_reverse() +
scale_fill_manual(values=c("cornflowerblue", "green3", "darkorange")) +
guides(color = FALSE, fill = FALSE) +
transition_states(year, transition_length = 1, state_length = 1, wrap= F) +
labs(title = 'Perú. Regiones según su VAB per cápita',
subtitle = "Año : {closest_state}",
caption = "Miles de Soles constantes de 1994 | Fuente: INEI") +
theme(
legend.position="none",
plot.title=element_text(size=18, hjust=0.5, face="bold", colour="grey20", vjust=-1),
plot.subtitle=element_text(size = 18, hjust=0.5, face="plain", color="grey20"),
plot.caption =element_text(size = 10, hjust=0.5, face="plain", color="grey20"),
axis.line=element_blank(),
plot.margin = margin(2,2, 2, 4, "cm"),
plot.background=element_blank(),
axis.text.x=element_blank(),
axis.text.y=element_blank(),
axis.ticks=element_blank(),
axis.title.x=element_blank(),
axis.title.y=element_blank(),
panel.grid.minor=element_blank(),
panel.grid.major=element_blank(),
panel.background=element_blank(),
panel.border=element_blank(),
panel.grid.major.x = element_line( size=.1, color="grey80", linetype = "dashed" ),
panel.grid.minor.x = element_line( size=.1, color="grey80", linetype = "dashed" )
)
Una vez tenemos el código representamos el gráfico animado con animate().
animate(plot_peru, width = 600, height = 600, fps = 5)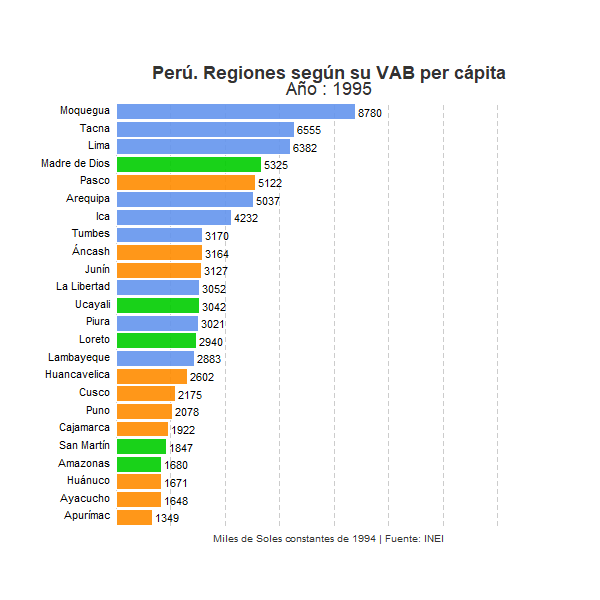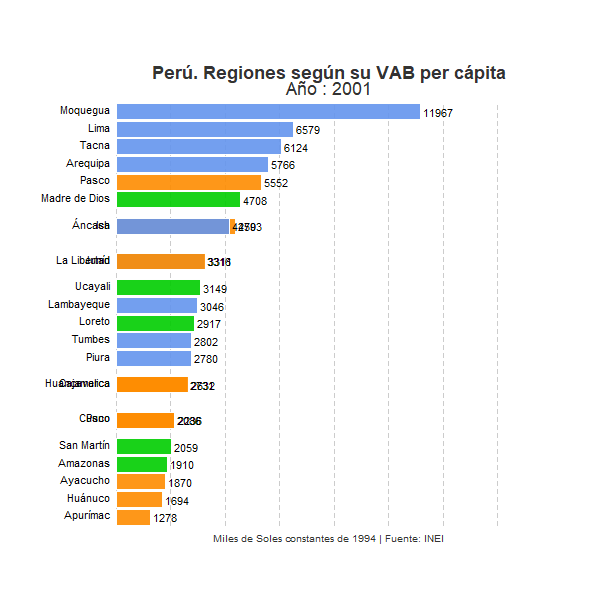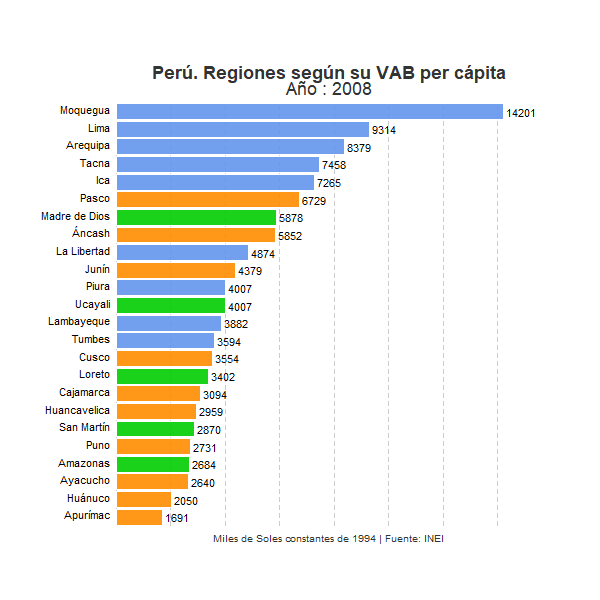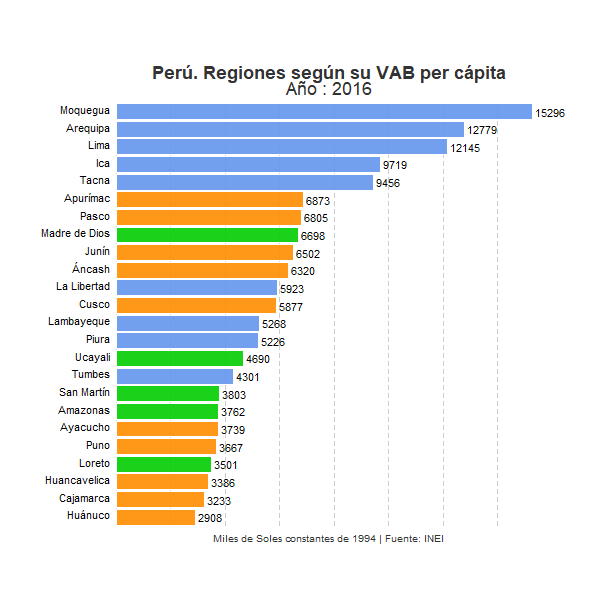
Vemos claramente la totalidad de regiones y cómo van evolucionando en el ranking a lo largo de los años. Entre ellas la región de Moquegua mantiene claramente una posición privilegiada a lo largo de todo el periodo. No obstante, se observa también que otro conjunto de regiones, principalmente regiones costeras como Lima, Arequipa, Ica o Tacna, han ido con el paso de los años acercando su nivel de renta per cápita con respecto al VAB por habitante de Moquegua. Por el contrario, en la parte inferior del ranking, un conjunto de regiones, principalmente regiones andinas, parecen consolidarse en las posiciones más desfavorables con respecto al resto de regiones peruanas. Sorprende especialmente el caso de Apurímac, región que se sitúa en la última posición a lo largo de la mayor parte del periodo analizado, pero que en 2016 mejora notablemente su posición en el ranking sitúandose en el quinto puesto. En este sentido conviene tener en cuenta el papel de la minería, actividad económica de gran productividad que representa una gran parte del VAB total en algunas regiones, especialmente en aquellas con economías menos desarrolladas y con una menor participación de actividades de servicios. El notable cambio sufrido por la región de Apurímac habrá tenido que ver, sin duda, con un incremento importante de la actividad extractiva en estos últimos años, lo que habrá contribuido sustancialmente al incremento del Valor Agregado Bruto de esta región. Consecuentemente, un posible análisis para un futuro post consistirá en identificar qué porcentaje del VAB por habitante de cada región responde a la actividad extractiva y en qué medida dicho sector influye en la posición relativa de las regiones mineras en el ranking que refleja nuestro gráfico.
Otra dinámica que podemos extraer de la evolución que refleja el gráfico es la creciente brecha existente entre las regiones peruanas en términos de VAB por habitante a lo largo de las últimas décadas. Sin duda, las regiones costeras del país, especialmente aquellas que por lo general presentan economías más diversificadas y modernas, han ido incrementando a lo largo de los años su VAB por habitante en gran medida, especialmente en relación con la mayor parte de regiones de sierra y selva del país. Todo parece indicar que las disparidades territoriales presentes históricamente en el país, especialmente aquellas disparidades existentes entre algunas de las regiones del litoral peruano y el resto del país, se han incrementado a lo largo del periodo analizado. El llamado milagro peruano no parece haber sido un fenómeno territorialmente equilibrado sino que parece haber contribuido a incrementar los desequilibrios regionales existentes en el país latinoamericano.
Por último, supongamos que queremos seleccionar únicamente los primeros puestos en el ranking. Para ello podemos filtrar nuestras observaciones con la función filter() de dplyr para reducir el número de observaciones a tener en cuenta en el gráfico final. A modo de ejemplo seleccionamos los diez primeros puestos del ranking tal y como vemos en el código siguiente.
Peru_rangos_top <- Peru %>%
group_by(year) %>%
mutate(rango = rank(-vabpc),
labels = paste0(" ", round(vabpc))) %>%
group_by(Nombre) %>%
filter(rango <=10) %>%
ungroup()
Consecuentemente, utilizando el nuevo dataframe Peru_rangos_top, y realizando pequeñas modificaciones al código anterior podemos visualizar la evolución de las regiones que ocupaban los primeros diez puestos en el ranking según su VAB por habitante. En esta ocasión cambiamos los colores utilizados en el gráfico previo, cambiamos el título, el subtítulo y algún otro aspecto del nuevo gráfico. Cómo hicimos previamente guardamos el nuevo gráfico, en este caso como plot_peru_top, y posteriormente procedemos a realizar la animación correspondiente con animate().
plot_peru_top <- ggplot(Peru_rangos_top, aes(rango, group = Nombre,
fill = Area)) +
geom_col(aes(y = vabpc), alpha = 0.9, color = "grey20") +
coord_flip(clip = "off", expand = FALSE) +
geom_text(aes(y = 0, label = paste(Nombre, " ")), vjust = 0.2, hjust = 1) +
geom_text(aes(y= vabpc, label = labels, hjust = 0, size = 1)) +
scale_y_continuous(labels = scales::comma) +
scale_x_reverse() +
scale_fill_manual(values=c("royalblue", "limegreen", "goldenrod4")) +
guides(color = FALSE, fill = FALSE) +
transition_states(year, transition_length = 1, state_length = 1, wrap= F) +
labs(title = 'Perú. Regiones según su VAB per cápita (Top 10)',
subtitle = "Año : {closest_state}",
caption = "Miles de Soles constantes de 1994 | Fuente: INEI") +
theme(
legend.position="none",
plot.title=element_text(size=18, hjust=0.5, face="bold", colour="grey20", vjust=-1),
plot.subtitle=element_text(size = 26, hjust=0.5, face="bold", color="grey20"),
plot.caption =element_text(size = 10, hjust=0.5, face="plain", color="grey20"),
axis.line=element_blank(),
plot.margin = margin(2,2, 2, 4, "cm"),
plot.background=element_blank(),
axis.text.x=element_blank(),
axis.text.y=element_blank(),
axis.ticks=element_blank(),
axis.title.x=element_blank(),
axis.title.y=element_blank(),
panel.grid.minor=element_blank(),
panel.grid.major=element_blank(),
panel.background=element_blank(),
panel.border=element_blank(),
panel.grid.major.x = element_line( size=.1, color="grey80", linetype = "dashed" ),
panel.grid.minor.x = element_line( size=.1, color="grey80", linetype = "dashed" )
)
animate(plot_peru_top, width = 600, height = 600, fps = 7)