Nombres en España
En el post previo, con el objetivo de exponer las principales funciones del paquete {dplyr}, examinamos la evolución de la popularidad de los nombres de los recién nacidos en Estados Unidos desde 1880 hasta 2017 en función de los datos que provee la Administración de Seguridad Social de este país. Para ello utilizamos el data frame babynames, que indica el número de registros de la tarjeta de la Seguridad Social norteamericana para cada nombre masculino y femenino que supere los cinco registros. Realizando dicho post me empecé a preguntar cómo habrá sido la evolución de los nombres en España, debido a los cambios en las preferencias, a lo largo de las últimas décadas. En este post realizaré una breve aproximación a la evolución que han sufrido los nombres masculinos y femeninos en España aunque la metodología escogida y los datos sobre los que trabajaremos difieren con respecto a los del post previo.
Para llevar a cabo este análisis haremos uso de los datos que provee el INEI.En su página podemos encontrar una lista de todos los nombres con frecuencia igual o mayor a 20 personas obtenidos de la Estadística del Padrón Continuo a fecha de 01 de enero de 2018. No obstante, a diferencia de la base de datos del post anterior para Estados Unidos donde se indicaba el número de personas que se registraba con cada uno de los nombres por año, en esta ocasión utilizaremos una base de datos que indica la edad promedio de los residentes al inicio del año 2018 y el número de personas que reciben cada uno de los nombres indicados.
En primer lugar descargamos los siguientes paquetes en nuestra sesión:
library(readxl)
library(tidyverse)
library(scales)
Nombres masculinos
En primer lugar creamos un nuevo data frame para los nombres masculinos que denominamos: hombres_por_edad_media.
# utilizamos la función read_excel() del paquete readxl
hombres_por_edad_media <- read_excel("./nombres_por_edad_media.xls", sheet = "Hom")
# las primeras observaciones del dataframe son:
head(hombres_por_edad_media)
## # A tibble: 6 x 4
## Orden Nombre Frec Media
## <chr> <chr> <dbl> <dbl>
## 1 1 ANTONIO 678425 55.9
## 2 2 JOSE 594144 61.1
## 3 3 MANUEL 590965 54.9
## 4 4 FRANCISCO 498934 57.4
## 5 5 DAVID 365196 30.5
## 6 6 JUAN 346867 55.7
# Vemos que, por ejemplo, según la base de datos utilizada existen 678425 personas con el nombre ANTONIO y su edad media sería de 55,9 años. Por tanto, a enero de 2018 ANTONIO sería el nombre masculino más frecuente en España, seguido por JOSE, MANUEL Y FRANCISCO.
Nombres femeninos
De forma similar creamos un nuevo data frame para los nombres femeninos al que nombraremos: mujeres_por_edad_media.
mujeres_por_edad_media <- read_excel("./nombres_por_edad_media.xls", sheet = "Muj")
# las primeras observaciones son:
head(mujeres_por_edad_media)
## # A tibble: 6 x 4
## Orden Nombre Frec Media
## <chr> <chr> <dbl> <dbl>
## 1 1 MARIA CARMEN 656276 57
## 2 2 MARIA 606048 48.6
## 3 3 CARMEN 391563 60.4
## 4 4 JOSEFA 276682 68
## 5 5 ANA MARIA 273319 51.2
## 6 6 ISABEL 266967 57.4
# MARIA CARMEN es el nombre femenino más frecuente, siendo su edad promedio de 57 años, seguido por MARIA y CARMEN, cuyas edades promedio son 48,6 y 60,4 respectivamente. Jamás habría imaginado que JOSEFA es el cuarto nombre femenino más frecuente.
Nombres masculinos más frecuentes según su edad promedio.
Nos interesa clasificar los nombres según su edad promedio. Para ello establecemos una serie de rangos de edad promedio de diez años cada uno. Sin embargo diferenciamos dos rangos de cinco años para los nombres cuya edad promedio es menor a 10 años por simple interés personal. Esto se debe a que intuimos que en este rango existirá una mayor variabilidad en los nombres debido a una creciente motivación por parte de los progenitores de elegir nombres más originales para sus recién nacidos.
Para establecer los rangos de edad creamos una nueva columna utilizando la función mutate() del paquete dplyry la función case_when() para identificar los nombres que corresponden a cada categoría. Además, tras ordenar el conjunto de nombres según los grupos de edad con group_by() seleccionamos únicamente las primeras 20 observaciones para conservar únicamente los nombres más frecuentes para cada uno de los grupos de edad establecidos.
hombres <- hombres_por_edad_media %>%
select(Nombre, Frec, Media)%>%
mutate(
grupos_edad =case_when(
Media >0 & Media <= 5 ~ "Edad promedio entre 0 y 5 años",
Media >5 & Media <= 10 ~"Edad promedio entre 6 y 10 años",
Media >10 & Media <= 20 ~"Edad promedio entre 11 y 20 años",
Media >20 & Media <= 30 ~"Edad promedio entre 21 y 30 años",
Media >30 & Media <= 40 ~"Edad promedio entre 31 y 40 años",
Media >40 & Media <= 50 ~"Edad promedio entre 41 y 50 años",
Media >50 & Media <= 60 ~"Edad promedio entre 51 y 60 años",
Media >60 & Media <= 70 ~"Edad promedio entre 60 y 70 años",
Media >70 & Media <= 80 ~"Edad promedio mayor de 71 años",
Media >80 & Media <= 90 ~"81-90",
TRUE ~ "91"
)
) %>%
group_by(grupos_edad,Nombre, Frec) %>%
select(grupos_edad, Nombre, Frec) %>%
arrange(grupos_edad) %>%
group_by(grupos_edad) %>%
top_n(20,Frec)
# El nuevo data frame está compuesto por 180 observaciones ( 20 nombres * 9 grupos de edad) y tres variables (grupos_edad, Nombre y Frec).
glimpse(hombres)
## Rows: 180
## Columns: 3
## Groups: grupos_edad [9]
## $ grupos_edad <chr> "Edad promedio entre 0 y 5 años", "Edad promedio entre ...
## $ Nombre <chr> "LEO", "ENZO", "DYLAN", "THIAGO", "NEIZAN", "IZEI", "EI...
## $ Frec <dbl> 16593, 9692, 6719, 5054, 1789, 788, 677, 662, 661, 619,...
# LEO, nombre cuya edad promedio se encuentra entre los 0 y 5 años (exactamente en 4,3) lidera este grupo de edad con 16593 registros. Esto no quiere decir que no existan LEO´s en otros rangos de edad sino que la edad promedio de personas con este nombre se encuentra en esta categoría. Para examinar el nombre de los recién nacidos, análisis que se asemejaría al realizado previamente con los nombres norteamericanos, podemos utilizar información sobre los nombres más frecuentes de los recién nacidos que también provee el INE. Por ejemplo, en 2017 LEO ocupaba el puesto 15 (2489 padres eligieron LEO como nombre para sus hijos en este año), siendo LUCAS, HUGO, MARTIN Y DANIEL los nombres más populares entre los recién nacidos varones. No obstante, en este post escogemos analizar los nombres según edad promedio con la intención de examinar los nombres de los residentes en 2018 desde una perspectiva distinta.
head(hombres)
## # A tibble: 6 x 3
## # Groups: grupos_edad [1]
## grupos_edad Nombre Frec
## <chr> <chr> <dbl>
## 1 Edad promedio entre 0 y 5 años LEO 16593
## 2 Edad promedio entre 0 y 5 años ENZO 9692
## 3 Edad promedio entre 0 y 5 años DYLAN 6719
## 4 Edad promedio entre 0 y 5 años THIAGO 5054
## 5 Edad promedio entre 0 y 5 años NEIZAN 1789
## 6 Edad promedio entre 0 y 5 años IZEI 788
Para ordenar siguiendo un criterio temporal adecuado los rangos de edad creados convertimos la variable grupos_edad en factor y establecemos los niveles que nos interesan de la siguiente forma:
hombres$grupos_edad <- factor(hombres$grupos_edad,
levels=c("Edad promedio entre 0 y 5 años",
"Edad promedio entre 6 y 10 años",
"Edad promedio entre 11 y 20 años",
"Edad promedio entre 21 y 30 años",
"Edad promedio entre 31 y 40 años",
"Edad promedio entre 41 y 50 años",
"Edad promedio entre 51 y 60 años",
"Edad promedio entre 60 y 70 años",
"Edad promedio mayor de 71 años"),
labels=c("Edad promedio entre 0 y 5 años",
"Edad promedio entre 6 y 10 años",
"Edad promedio entre 11 y 20 años",
"Edad promedio entre 21 y 30 años",
"Edad promedio entre 31 y 40 años",
"Edad promedio entre 41 y 50 años",
"Edad promedio entre 51 y 60 años",
"Edad promedio entre 60 y 70 años",
"Edad promedio mayor de 71 años"))
Visualización de los nombres masculinos más frecuentes según edad promedio
En primer volvemos a cargar el theme diseñado por Tradfford Data Lab llamado theme_lab() que podemos encontrar en el siguiente enlace:
source("https://github.com/traffordDataLab/assets/raw/master/theme/ggplot2/theme_lab.R")
Utilizando facets queremos identificar, según los rangos de edad establecidos previamente, los 20 nombres en cada rango más comunes. Como hemos señalado, esto no quiere decir que dichos nombres se encuentren únicamente en dicho rango de edad, pero la información obtenida nos permite hacernos una idea de qué nombres están incrementando su popularidad recientemente, cuáles son los nombres más utilizados en 2018 y qué nombres están en camino de su desaparición (no obstante, tengamos en cuenta que la base de datos con la que trabajamos incluye solo los nombres con más de 20 registros, por lo que los nombres que de verdad se encuentran en gran peligro de desaparecer no se encuentran, lamentablemente, en nuestro data frame).
ggplot(hombres, aes(reorder(Nombre, Frec), Frec)) +
geom_col(fill = "#fc6721",
alpha = 0.8,
size= 2)+
coord_flip()+
facet_wrap(~grupos_edad, scales= "free_y", ncol=2)+
labs(title = "Nombres masculinos más comunes",
subtitle = "Organizados en categorías según su edad promedio \n",
caption = "Fuente: INE | @Ruben46563154",
x = "", y = "",
fill = NULL) +
theme_lab()+
theme(panel.grid.major.x = element_blank(),
axis.text.y= element_text(size = 8, hjust = 1),
axis.text.x= element_text(size = 8),
plot.title = element_text(size = 18,
face = "bold",
hjust = 0.5),
plot.subtitle = element_text(size=14,
face = "plain",
hjust = 0.5)) +
scale_y_continuous(labels = comma)+
geom_hline(yintercept=c(200000, 400000,600000),
color = "lightgrey",
linetype = "dashed")+
geom_text(aes(label = Frec, y = Frec + 0.05),
hjust = 0,
color = "grey40",
size = 2.8)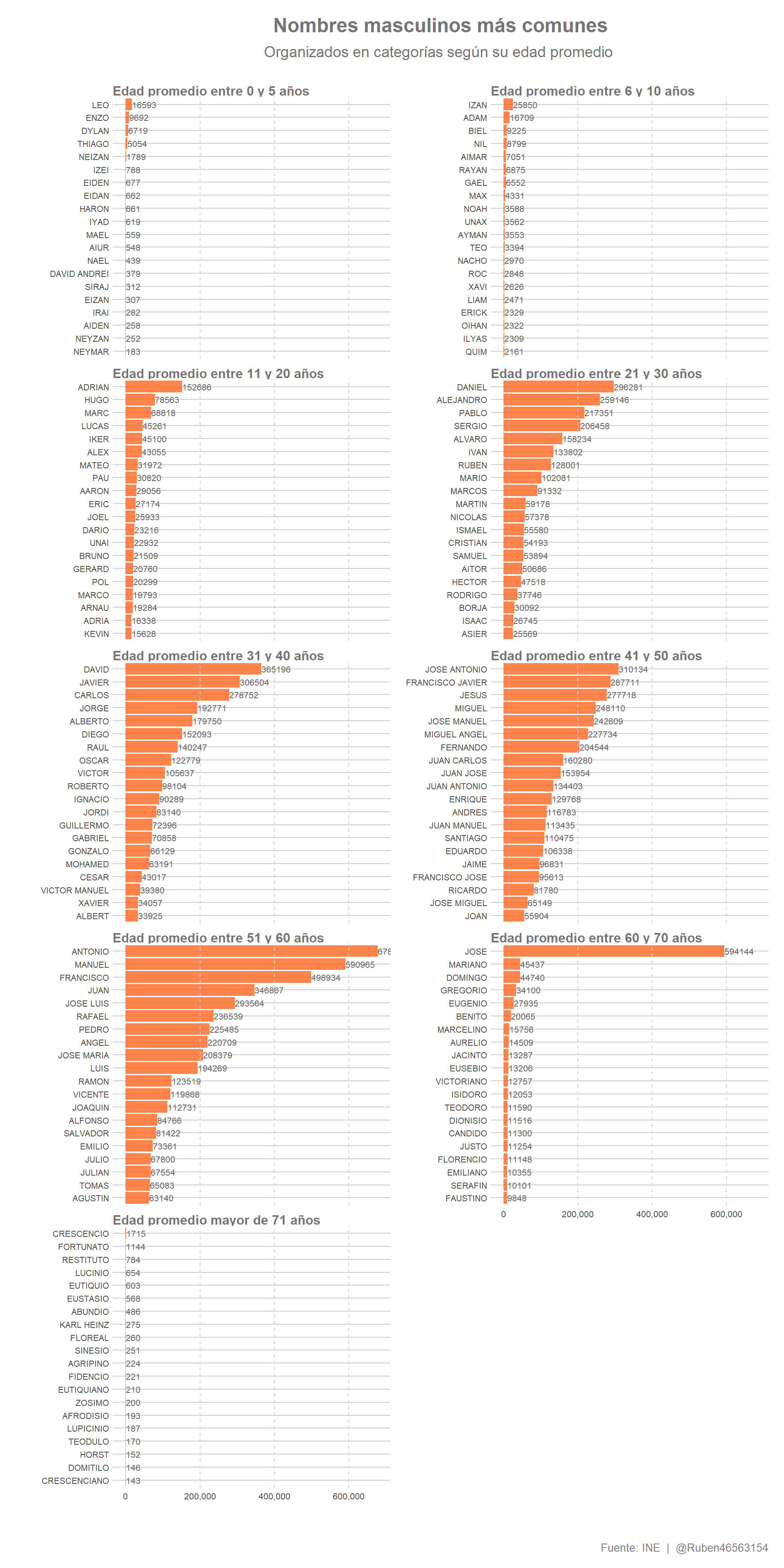
Este post no tiene como objetivo realizar un análisis exhaustivo de la evolución de los nombres en España sino que, con la excusa de los nombres mostrar un ejemplo de cómo manipular los datos, crear categorías en base a un criterio determinado y cómo realizar un gráfico que refleje dichas categorías. No obstante, del gráfico presentado podemos sacar algunas reflexiones interesantes.
Entre los nombres de moda, es decir, entre los nombres de niños de menor edad, se observan notables influencias de deportistas famosos, como por ejemplo Leo o Neymar para el rango de edad 0-5 o Iker Y Pau para el rango de edad 11-20.
También encontramos nombres de origen extranjero prácticamente desconocidos en el país hasta hace poco, como pueden ser Iyad, Siraj, Haron, nombres de origen Árabe fruto sin duda del creciente fenómeno de la inmigración.
Resulta curioso encontrar distintas variedades de algún nombre de origen extranjero, en su mayoría inglés, donde no parece existir un claro consenso en su plasmación escrita, como por ejemplo Neizan-Neyzan-Eizan-Izan o Eiden-Eidan-Aiden.
Es evidente que existe una creciente preferencia hacia nombres más cortos, siendo cada vez menos populares los nombres compuestos, e incluso estando de moda acotaciones de nombres ya existentes como Biel(Gabriel), Teo (Teodoro, Teófilo), Xavi (Xavier), Nacho (Ignacio) o Quim (Joaquim).
Los nombres regionales, como por ejemplo nombres de origen catalán o del País Vasco, parecen también estar en auge. Véase por ejemplo los nombres de Izei y Oihan (abeto y bosque en Euskera), Irai, Aiur, Roc, Quim entre otros.
A pesar de las nuevas tendencias que se observan entre los nombres de los niños de menor edad los gráficos muestran claramente que los nombres masculinos que todavía predominan en España son aquellos de corte más tradicional (al menos desde mi percepción como persona en los 30´s) como Antonio, José, Manuel, Francisco, David, José Antonio, etc. Cómo cabía esperar los rangos de edad promedio de estos nombres se sitúan especialmente entre los 30 y 60 años.
Por el contrario, los gráficos también muestran la existencia de un considerable conjunto de nombres que se encuentran en peligro de extinción. Aunque como hemos indicado previamente la base de datos utilizada no incluye los nombres con frecuencia menor a 20, entre los que se encontrarían aquellos en mayor peligro de desaparecer, podemos identificar una serie de nombres en un rango de edad promedio mayor a 71 años con relativamente poca frecuencia. Véase, por ejemplo, nombres como Crescenciano, Domitilo, Teódulo o Afrodisio entre otros.
Para detectar, por ejemplo, los nombres en mayor peligro de extinción entre los que se incluyen en nuestra base de datos podemos indicar, por ejemplo, que se nos muestre aquellos nombres con una frecuencia menor a 30 y cuya edad promedio sea superior a 75 años de la siguiente forma:
hombres_por_edad_media %>%
filter( Frec < 30 & Media > 75)
## # A tibble: 5 x 4
## Orden Nombre Frec Media
## <chr> <chr> <dbl> <dbl>
## 1 18717 FREDERICK GEORGE 28 75.2
## 2 20841 ACINDINO 24 78.1
## 3 22119 PROGRESO 23 75.4
## 4 23235 AUXILIO 21 78.4
## 5 25021 VITORES 20 75.5
# ¿¿Frederick George?? ... eso no parece producto nacional, ¿no?. VITORES, AUXILIO, PROGRESO o ACINDINO si se encuentran en un grave peligro de desaparecer de la onomástica actual.
Nombres femeninos más frecuentes según su edad promedio.
Al igual que hemos hecho con los nombres masculinos procedemos ahora a examinar la evolución de los nombres femeninos utilizando la misma metodología a la utilizada en el apartado previo.
mujeres <- mujeres_por_edad_media %>%
select(Nombre, Frec, Media) %>%
mutate(
grupos_edad = case_when(
Media >0 & Media <= 5 ~ "Edad promedio entre 0 y 5 años",
Media >5 & Media <= 10 ~"Edad promedio entre 6 y 10 años",
Media >10 & Media <= 20 ~"Edad promedio entre 11 y 20 años",
Media >20 & Media <= 30 ~"Edad promedio entre 21 y 30 años",
Media >30 & Media <= 40 ~"Edad promedio entre 31 y 40 años",
Media >40 & Media <= 50 ~"Edad promedio entre 41 y 50 años",
Media >50 & Media <= 60 ~"Edad promedio entre 51 y 60 años",
Media >60 & Media <= 70 ~"Edad promedio entre 60 y 70 años",
Media >70 & Media <= 90 ~"Edad promedio mayor de 71 años",
Media >90 & Media <= 100 ~"90-100",
TRUE ~ "91"
)
) %>%
group_by(grupos_edad, Nombre, Frec) %>%
select(grupos_edad, Nombre, Frec) %>%
arrange(grupos_edad) %>%
group_by(grupos_edad) %>%
top_n(20,Frec)
# las primeras observaciones del nuevo data frame son:
head(mujeres)
## # A tibble: 6 x 3
## # Groups: grupos_edad [1]
## grupos_edad Nombre Frec
## <chr> <chr> <dbl>
## 1 Edad promedio entre 0 y 5 años CHLOE 6007
## 2 Edad promedio entre 0 y 5 años MIA 5102
## 3 Edad promedio entre 0 y 5 años ARLET 3018
## 4 Edad promedio entre 0 y 5 años INDIA 1415
## 5 Edad promedio entre 0 y 5 años JANNAT 987
## 6 Edad promedio entre 0 y 5 años ISRAA 844
Debemos de nuevo ordenar cronológicamente los rangos de edad creados y, para ello, convertimos de nuevo dicha variable en factor y establecemos los niveles que nos interesan.
mujeres$grupos_edad <- factor(mujeres$grupos_edad,
levels=c("Edad promedio entre 0 y 5 años",
"Edad promedio entre 6 y 10 años",
"Edad promedio entre 11 y 20 años",
"Edad promedio entre 21 y 30 años",
"Edad promedio entre 31 y 40 años",
"Edad promedio entre 41 y 50 años",
"Edad promedio entre 51 y 60 años",
"Edad promedio entre 60 y 70 años",
"Edad promedio mayor de 71 años"),
labels=c("Edad promedio entre 0 y 5 años",
"Edad promedio entre 6 y 10 años",
"Edad promedio entre 11 y 20 años",
"Edad promedio entre 21 y 30 años",
"Edad promedio entre 31 y 40 años",
"Edad promedio entre 41 y 50 años",
"Edad promedio entre 51 y 60 años",
"Edad promedio entre 60 y 70 años",
"Edad promedio mayor de 71 años"))
Visualización de los nombres femeninos más frecuentes según edad promedio
ggplot(mujeres, aes(reorder(Nombre, Frec, sum), Frec)) +
geom_col(fill = "#fc6721",
alpha = 0.8,
size= 2)+
coord_flip()+
facet_wrap(~grupos_edad, scales= "free_y", ncol=2)+
labs(title = "Nombres femeninos más comunes",
subtitle = "Organizados en categorías según su edad promedio \n",
caption = "Fuente: INE | @Ruben46563154",
x = "", y = "",
fill = NULL) +
theme_lab()+
theme(panel.grid.major.x = element_blank(),
axis.text.y= element_text(size = 8, hjust = 1),
axis.text.x= element_text(size = 8),
plot.title = element_text(size = 18,
face = "bold",
hjust = 0.5),
plot.subtitle = element_text(size=14,
face = "plain",
hjust = 0.5)) +
scale_y_continuous(labels = comma)+
geom_hline(yintercept=c(200000, 400000,600000),
color = "lightgrey",
linetype = "dashed")+
geom_text(aes(label = Frec, y = Frec + 0.05),
hjust = 0,
color = "grey40",
size = 2.8)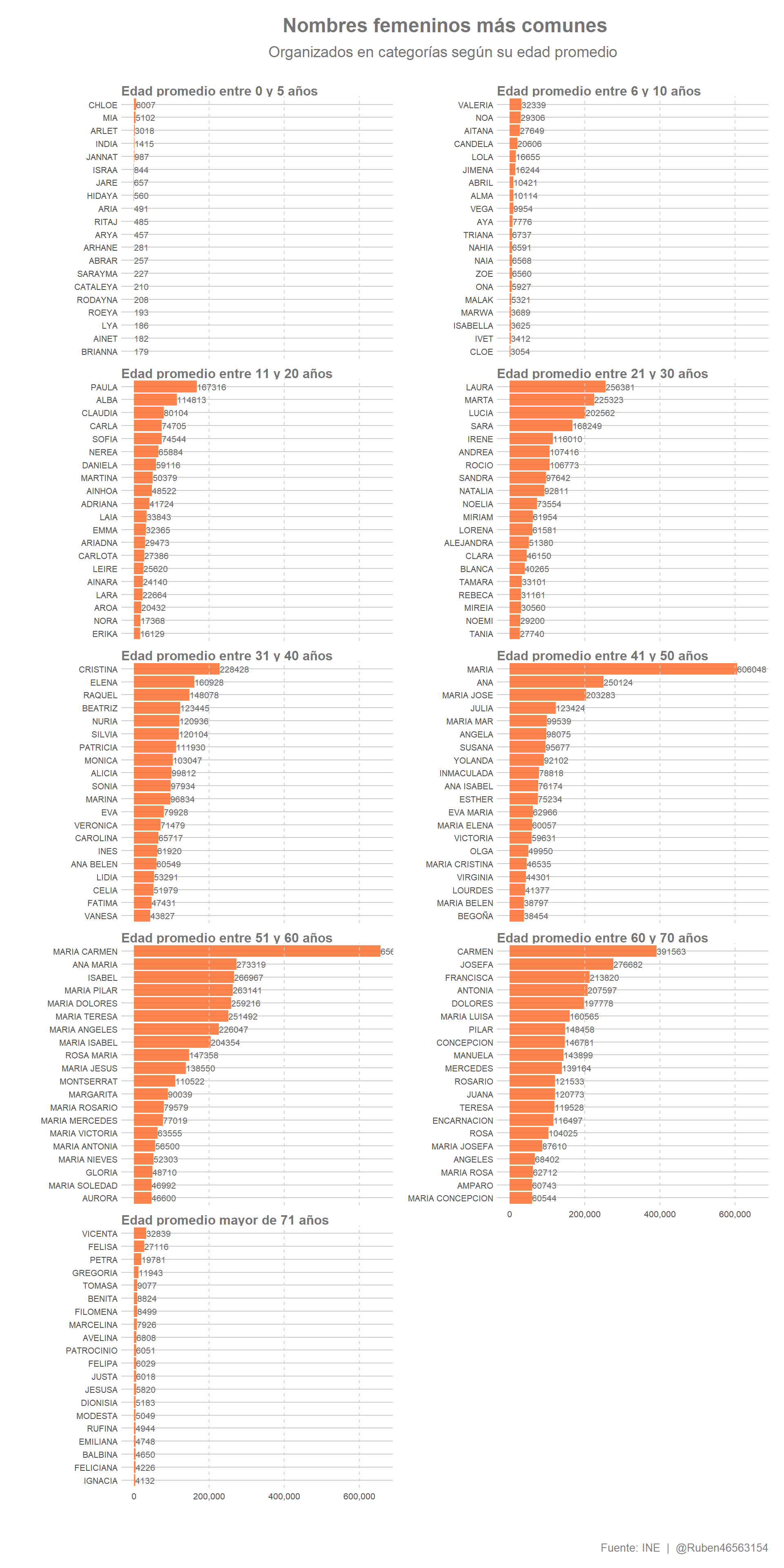
Al igual que sucedía con los nombres masculinos, los gráficos realizados muestran información interesante acerca de la evolución de los nombres femeninos en España en las últimas décadas. De nuevo, sin ánimo de ser exhaustivos, detectamos algunos patrones de comportamiento en su evolución que se asemejan en gran medida a los observados para los nombres masculinos:
La influencia de personajes conocidos no escapa a los nombres femeninos de las niñas de menor edad, bien sea a consecuencia de populares series de televisión, cantantes o actrices. Véase por ejemplo los nombres de Aria, Arya, Brianna.
También encontramos nuevos nombres de origen extranjero, algunos de los cuales yo personalmente no había oído jamás, vinculados posiblemente a la población migrante como puede Jannat, Ritaj, Hidaya o Abrar.
Se observa también una creciente preferencia por nombres simples, y de menor longitud, en ocasiones fruto también de acotaciones de nombres conocidos como Lola (Dolores se llamaba Lola), Candela (Candelaria), Laia (Eulalia).
La preferencia por los nombres compuestos, especialmente utilizando como primer nombre María fue especialmente notable en los nombres cuyo promedio se encuentra entre los 51-60 años, aunque también entre los 41-50 y los 60-70. Todo parece indicar que cada vez veremos menos niñas con los nombres de María Carmen, María Pilar, María Teresa, María Ángeles, María José, María Luisa, María Victoria, María Antonia o María Soledad, entre otros … A no ser, claro, que en el futuro se recuperen viejas tendencias.
Aún con todo, el nombre más común a principios de 2018 en España es María Carmen, seguido por María y Carmen. Nombres que se encuentran en rangos de edad promedio entre los 50 y los 70 años.
De nuevo comprobamos la existencia de nombres femeninos también en importante peligro de extinción. A partir de los gráficos podemos identificar nombres como Ignacia, Feliciana, Balbina, Emiliana o Rufina, nombres cuya edad promedio está en más de 71 años. No obstante, y teniendo en cuenta que el INEI no informa de nombres de menos de 20 registros, podemos examinar los nombres femeninos en mayor peligro de extinción de la siguiente forma:
mujeres_por_edad_media %>%
filter(Frec < 30 & Media >80)
## # A tibble: 3 x 4
## Orden Nombre Frec Media
## <chr> <chr> <dbl> <dbl>
## 1 20243 PARMENIA 26 80.8
## 2 24461 SERVILIANA 21 80.1
## 3 25491 SANCHO ABARCA 20 80.2
# ¿Sancho Abarca? De este nombre solo sabía que era un pueblo de las Cinco Villas de la provincia de Zaragoza, pero ¿es también un nombre femenino? Será quizá un nombre utilizado en la zona. Por su parte PARMENIA y SERVILIANA son los nombres de 26 y 21 personas respectivamente, cuyas edades promedio superan los 80 años.
# Si reducimos la edad promedio, pero también la frecuencia obtenemos otro conjunto de nombres también en peligro de desaparecer en las próximas décadas
mujeres_por_edad_media %>%
filter(Frec ==20 & Media > 75)
## # A tibble: 4 x 4
## Orden Nombre Frec Media
## <chr> <chr> <dbl> <dbl>
## 1 24843 DICTINA 20 76
## 2 24850 DOMBINA 20 78.1
## 3 24975 HEREDIA 20 77.4
## 4 25491 SANCHO ABARCA 20 80.2
# DICTINIA, DOMBINA y HEREDIA.