Re
En este post se expondrá cómo realizar mapas de España utilizando archivos shapefile y el paquete ggplot2. Los archivos shapefiles los descargaremos de la web y los datos los descargaremos del INE.
Paquetes de R
# para manipular dataframes
library(tidyverse)
# para importar archivos shapefiles
library(rgdal)
# Para transformar los archivos shapefiles
library(broom)
Comunidades Autónomas Españolas
En primer lugar vamos a exponer cómo realizar un mapa de España diferenciando las distintas Comunidades Autónomas que la componen. Para ello descargamos el archivo shapefile con la información geográfica de las autonomías españolas de arcgis.com. Nótese que un archivo shapefile (SHP) es un formato de datos espaciales de representación vectorial desarrollado por la compañía ESRI que sirve para almacenar información de la ubicación de distintas entidades geográficas. Dicha información geométrica se puede representar con puntos, líneas o polígonos (áreas).
La función readOGR()del paquete rgdal permite leer archivos shapefile (.shp) que en nuestro caso hemos descargado previamente desde la página mencionada y guardado en una carpeta de nuestro ordenador. Por su parte, con la función tidy() del paquete broom creamos un dataframe (data_ccaa) que nos servirá para su representación gráfica posterior.
Descarga y formato de archivos shapefile
setwd("C:/Users/Usuario/Desktop/r_que_r/r_que_r/content/datasets/ComunidadesAutonomas_ETRS89_30N")
# Guardamos el archivo shapefile
shapefile_ccaa <- readOGR("Comunidades_Autonomas_ETRS89_30N.shp")
## OGR data source with driver: ESRI Shapefile
## Source: "C:\Users\Usuario\Desktop\r_que_r\r_que_r\content\datasets\ComunidadesAutonomas_ETRS89_30N\Comunidades_Autonomas_ETRS89_30N.shp", layer: "Comunidades_Autonomas_ETRS89_30N"
## with 19 features
## It has 3 fields
# Para convertir el archivo shapefile en un dataframe utilizamos la función tidy()
data_ccaa <- tidy(shapefile_ccaa)
# primeras observaciones del dataset
head(data_ccaa)
## # A tibble: 6 x 7
## long lat order hole piece group id
## <dbl> <dbl> <int> <lgl> <chr> <chr> <chr>
## 1 323065. 4288359. 1 FALSE 1 0.1 0
## 2 323295. 4288263. 2 FALSE 1 0.1 0
## 3 323997. 4288366. 3 FALSE 1 0.1 0
## 4 324629. 4287514. 4 FALSE 1 0.1 0
## 5 325061. 4287374. 5 FALSE 1 0.1 0
## 6 325720. 4286706. 6 FALSE 1 0.1 0
Vemos que el dataframe creado no contiene los nombres de las distintas CCAA españolas pero, en cambio, dicho dataframe indica el “id” de las mismas. No obstante, el archivo shapefile original si contiene información de los nombres de las Comunidades Autónomas. Por tanto, podemos extraer los nombres en un nuevo dataframe (nombres_ccaa) y añadir el “id” de cada una de las regiones. El objetivo es, posteriormente, unir los dos dataframes por la columna común “id”.
nombres_ccaa <- data.frame(shapefile_ccaa$Texto)
head(nombres_ccaa)
## shapefile_ccaa.Texto
## 1 AndalucÃa
## 2 Aragón
## 3 Principado de Asturias
## 4 Islas Baleares
## 5 Canarias
## 6 Cantabria
nombres_ccaa$id <- as.character(seq(0, nrow(nombres_ccaa)-1))
head(nombres_ccaa)
## shapefile_ccaa.Texto id
## 1 AndalucÃa 0
## 2 Aragón 1
## 3 Principado de Asturias 2
## 4 Islas Baleares 3
## 5 Canarias 4
## 6 Cantabria 5
data_ccaa_mapa <- left_join(data_ccaa, nombres_ccaa, by = "id")
head(data_ccaa_mapa)
## # A tibble: 6 x 8
## long lat order hole piece group id shapefile_ccaa.Texto
## <dbl> <dbl> <int> <lgl> <chr> <chr> <chr> <fct>
## 1 323065. 4288359. 1 FALSE 1 0.1 0 AndalucÃa
## 2 323295. 4288263. 2 FALSE 1 0.1 0 AndalucÃa
## 3 323997. 4288366. 3 FALSE 1 0.1 0 AndalucÃa
## 4 324629. 4287514. 4 FALSE 1 0.1 0 AndalucÃa
## 5 325061. 4287374. 5 FALSE 1 0.1 0 AndalucÃa
## 6 325720. 4286706. 6 FALSE 1 0.1 0 AndalucÃa
Mapa de las Comunidades Autónomas usando ggplot
Para representar en un mapa utilizando la información del dataframe obtenido del archivo shapefile podemos utilizar el paquete ggplot2 y la función geom_polygon(). De esta forma, utilizando las funciones de este paquete, podemos customizar el gráfico y modificar sus características.
data_ccaa_mapa %>%
ggplot() +
geom_polygon(aes( x= long, y = lat, group = group),
fill = "violetred4",
color = "white") +
theme_minimal() +
theme(
axis.line = element_blank(),
axis.text = element_blank(),
axis.title = element_blank(),
axis.ticks = element_blank(),
panel.background = element_rect(colour= "darkgrey", size= 0.5)) +
ggtitle("Comunidades Autónomas Españolas")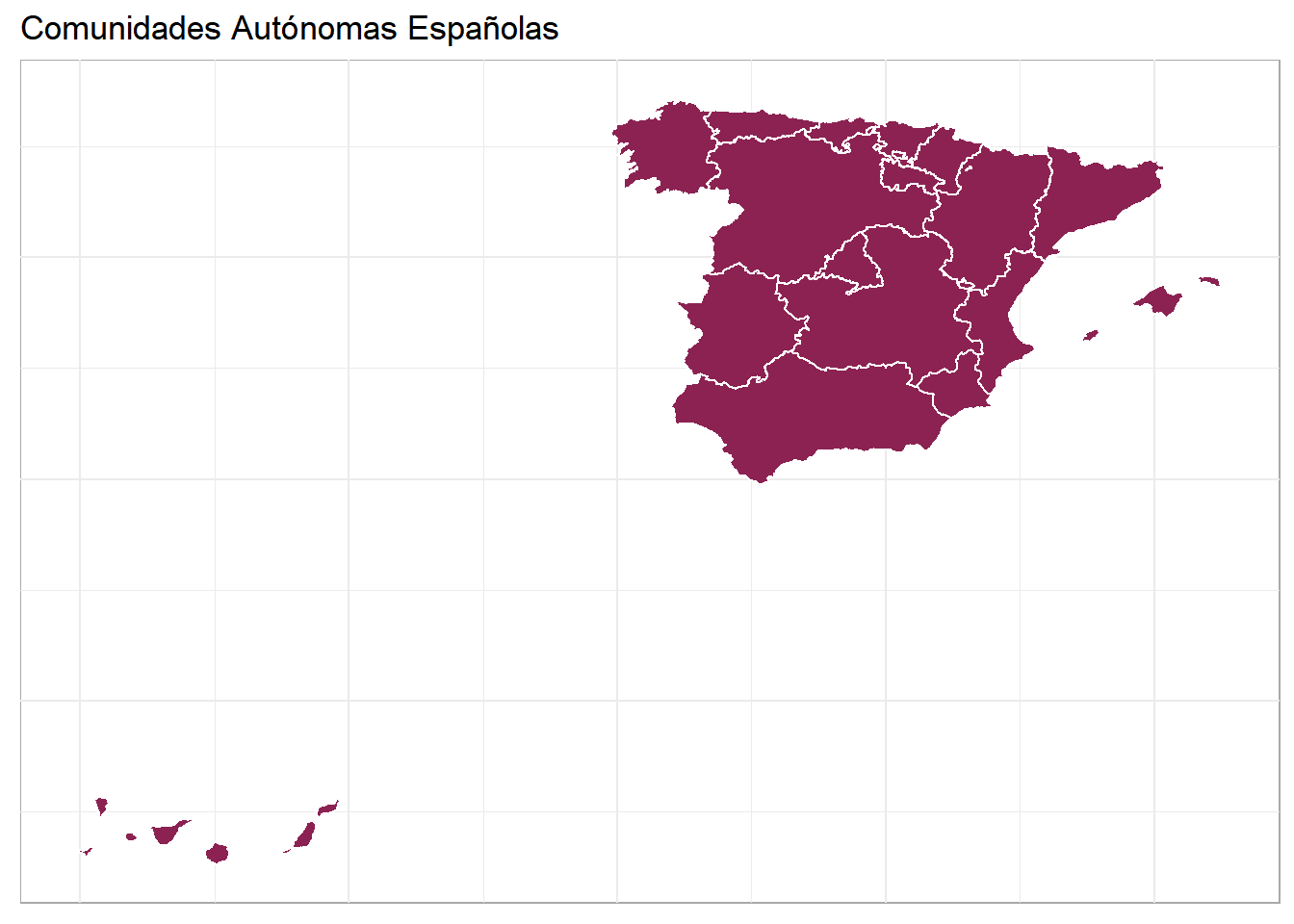
Provincias Españolas
En este subapartado vamos a realizar el mismo análisis realizado previamente pero identificando en esta ocasión las provincias españolas. Para ello, al igual que hicimos en el ejercicio anterior descargamos el archivo shapefile de arcgis.com.
Descarga y formato de archivos shapefile
setwd("C:/Users/Usuario/Desktop/r_que_r/r_que_r/content/datasets/Provincias_ETRS89_30N")
# Guardamos el archivo shapefile
shapefile_provincias <- readOGR("Provincias_ETRS89_30N.shp")
## OGR data source with driver: ESRI Shapefile
## Source: "C:\Users\Usuario\Desktop\r_que_r\r_que_r\content\datasets\Provincias_ETRS89_30N\Provincias_ETRS89_30N.shp", layer: "Provincias_ETRS89_30N"
## with 52 features
## It has 5 fields
# Para convertir el archivo shapefile en un dataframe utilizamos la función tidy()
data_provincias <- tidy(shapefile_provincias)
# primeras observaciones del dataset
head(data_provincias)
## # A tibble: 6 x 7
## long lat order hole piece group id
## <dbl> <dbl> <int> <lgl> <chr> <chr> <chr>
## 1 497824. 4784874. 1 FALSE 1 0.1 0
## 2 498457. 4784220. 2 FALSE 1 0.1 0
## 3 498532. 4783866. 3 FALSE 1 0.1 0
## 4 498382. 4783793. 4 FALSE 1 0.1 0
## 5 498946. 4783509. 5 FALSE 1 0.1 0
## 6 499046. 4782937. 6 FALSE 1 0.1 0
De nuevo vemos que el dataset creado contiene información del “id” pero no los nombres de las distintas provincias españolas. Obtenemos de nuevo los nombres del archivo shapefile original y realizamos el mismo ejercicio del punto anterior para obtener en nuestro dataframe una columna para el “id” y otra con el nombre de cada provincia española junto a la información de cada provincia para su representación gráfica.
nombres_provincias <- data.frame(shapefile_provincias$Texto)
head(nombres_provincias)
## shapefile_provincias.Texto
## 1 Ã\201lava
## 2 Albacete
## 3 Alicante
## 4 AlmerÃa
## 5 Ã\201vila
## 6 Badajoz
nombres_provincias$id <- as.character(seq(0, nrow(nombres_provincias)-1))
head(nombres_provincias)
## shapefile_provincias.Texto id
## 1 Ã\201lava 0
## 2 Albacete 1
## 3 Alicante 2
## 4 AlmerÃa 3
## 5 Ã\201vila 4
## 6 Badajoz 5
data_provincias_mapa <- left_join(data_provincias, nombres_provincias, by = "id")
head(data_provincias_mapa)
## # A tibble: 6 x 8
## long lat order hole piece group id shapefile_provincias.Texto
## <dbl> <dbl> <int> <lgl> <chr> <chr> <chr> <fct>
## 1 497824. 4784874. 1 FALSE 1 0.1 0 "Ã\u0081lava"
## 2 498457. 4784220. 2 FALSE 1 0.1 0 "Ã\u0081lava"
## 3 498532. 4783866. 3 FALSE 1 0.1 0 "Ã\u0081lava"
## 4 498382. 4783793. 4 FALSE 1 0.1 0 "Ã\u0081lava"
## 5 498946. 4783509. 5 FALSE 1 0.1 0 "Ã\u0081lava"
## 6 499046. 4782937. 6 FALSE 1 0.1 0 "Ã\u0081lava"
Mapa de las Provincias usando ggplot
Utilizamos el mismo código para realizar un mapa similar al anterior pero, en este caso, identificando las provincias españolas.
data_provincias_mapa %>%
ggplot() +
geom_polygon(aes( x= long, y = lat, group = group),
fill = "violetred4",
color = "white") +
theme_minimal() +
theme(
axis.line = element_blank(),
axis.text = element_blank(),
axis.title = element_blank(),
axis.ticks = element_blank(),
panel.background = element_rect(colour= "darkgrey", size= 0.5)) +
ggtitle("Provincias Españolas")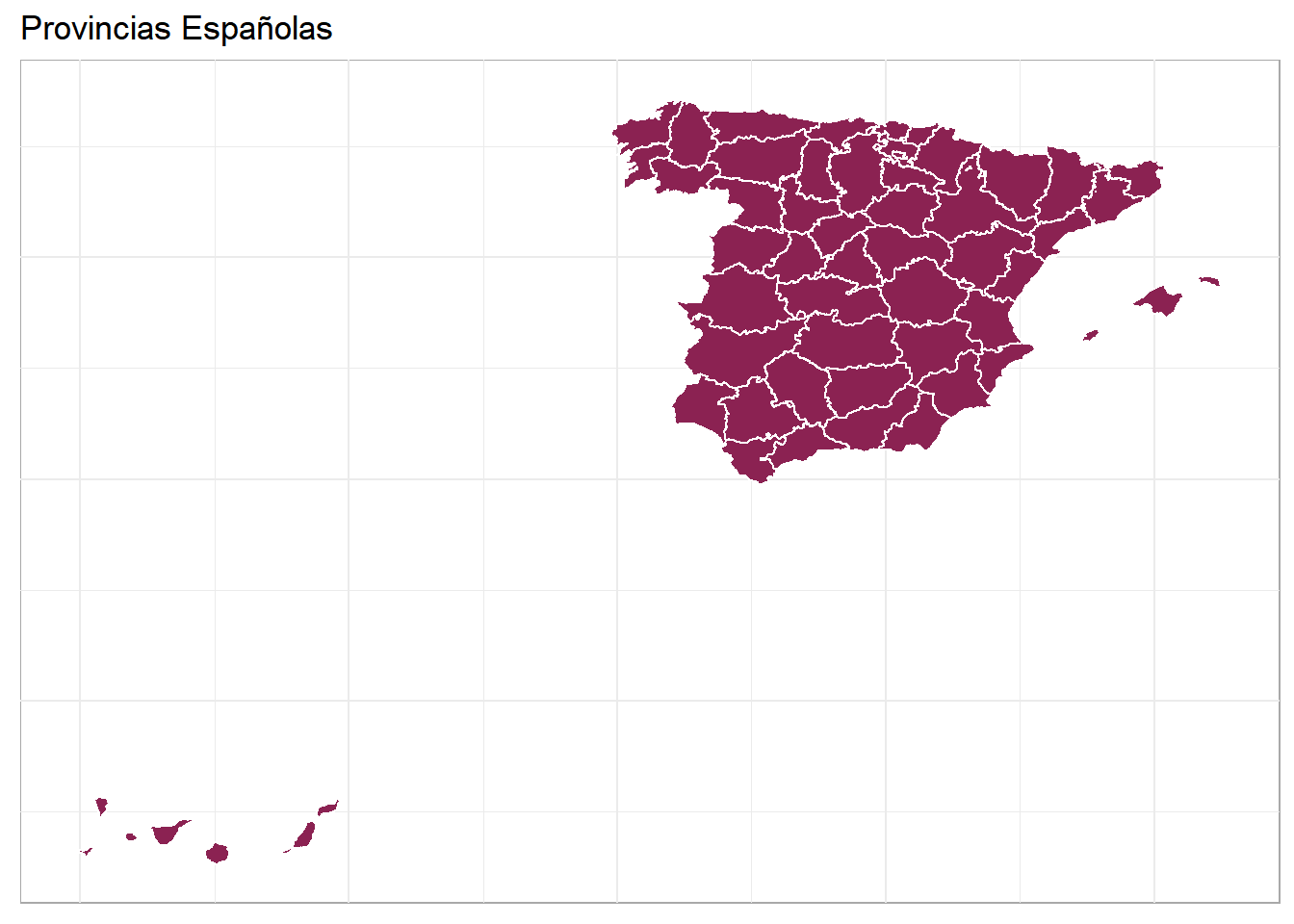
Municipios Españoles
Por último realizamos un mapa donde se representen los distintos municipios de España. En este caso el archivo shapefile con información geográfica de los municipios españoles lo descargamos de opendata.esri.es. La operativa es similar a la realizada en el punto anterior aunque en lugar de utilizar los nombres de los municipios utilizaremos los códigos provistos por el INE (CODIGOINE).
Descarga y formato de archivos shapefile
setwd("C:/Users/Usuario/Desktop/r_que_r/r_que_r/content/datasets/Municipios_IGN")
# Guardamos el archivo shapefile
shapefile_municipios <- readOGR("Municipios_IGN.shp")
## OGR data source with driver: ESRI Shapefile
## Source: "C:\Users\Usuario\Desktop\r_que_r\r_que_r\content\datasets\Municipios_IGN\Municipios_IGN.shp", layer: "Municipios_IGN"
## with 8205 features
## It has 10 fields
## Integer64 fields read as strings: OBJECTID
# Para convertir el archivo shapefile en un dataframe utilizamos la función tidy()
data_municipios <- tidy(shapefile_municipios)
# primeras observaciones del dataset
head(data_municipios)
## # A tibble: 6 x 7
## long lat order hole piece group id
## <dbl> <dbl> <int> <lgl> <chr> <chr> <chr>
## 1 -1.58 42.4 1 FALSE 1 0.1 0
## 2 -1.58 42.4 2 FALSE 1 0.1 0
## 3 -1.58 42.4 3 FALSE 1 0.1 0
## 4 -1.58 42.4 4 FALSE 1 0.1 0
## 5 -1.58 42.4 5 FALSE 1 0.1 0
## 6 -1.58 42.4 6 FALSE 1 0.1 0
El código de los municipios se encuentra en el archivo original con el nombre CODIGOINE. Guardamos los códigos en un nuevo data frame llamado codigo_municipios. Al igual que hemos hecho anteriormente identificamos el “id” de cada municipio, que llamamos codigo_municipios, y, posteriormente, utilizando la función left_join() unimos los dos dataframes en uno llamado data_municipios_mapa que nos servirá para realizar el mapa final.
codigo_municipios <- data.frame(shapefile_municipios$CODIGOINE)
head(codigo_municipios)
## shapefile_municipios.CODIGOINE
## 1 31164
## 2 31165
## 3 31166
## 4 31167
## 5 31168
## 6 19306
codigo_municipios$id <- as.character(seq(0, nrow(codigo_municipios)-1))
head(codigo_municipios)
## shapefile_municipios.CODIGOINE id
## 1 31164 0
## 2 31165 1
## 3 31166 2
## 4 31167 3
## 5 31168 4
## 6 19306 5
data_municipios_mapa <- left_join(data_municipios, codigo_municipios, by = "id") %>%
mutate(codigo_ine = as.character(`shapefile_municipios.CODIGOINE`)) %>%
select(-`shapefile_municipios.CODIGOINE`)
head(data_municipios_mapa)
## # A tibble: 6 x 8
## long lat order hole piece group id codigo_ine
## <dbl> <dbl> <int> <lgl> <chr> <chr> <chr> <chr>
## 1 -1.58 42.4 1 FALSE 1 0.1 0 31164
## 2 -1.58 42.4 2 FALSE 1 0.1 0 31164
## 3 -1.58 42.4 3 FALSE 1 0.1 0 31164
## 4 -1.58 42.4 4 FALSE 1 0.1 0 31164
## 5 -1.58 42.4 5 FALSE 1 0.1 0 31164
## 6 -1.58 42.4 6 FALSE 1 0.1 0 31164
Mapa de los Municipios usando ggplot
Una vez tenemos el dataframe con la información geográfica de los municipios españoles junto al código (CODIGOINE) y el “id” de cada uno de ellos procedemos a realizar el mapa correspondiente utilizando ggplot2 de la misma forma que hemos hecho en los subapartados previos.
data_municipios_mapa %>%
ggplot() +
geom_polygon(aes( x= long, y = lat, group = group),
fill = "violetred4",
color = "white",
size = 0.05) +
theme_minimal() +
theme(
axis.line = element_blank(),
axis.text = element_blank(),
axis.title = element_blank(),
axis.ticks = element_blank(),
panel.background = element_rect(colour= "darkgrey", size= 0.5)) +
ggtitle("Municipios Españoles")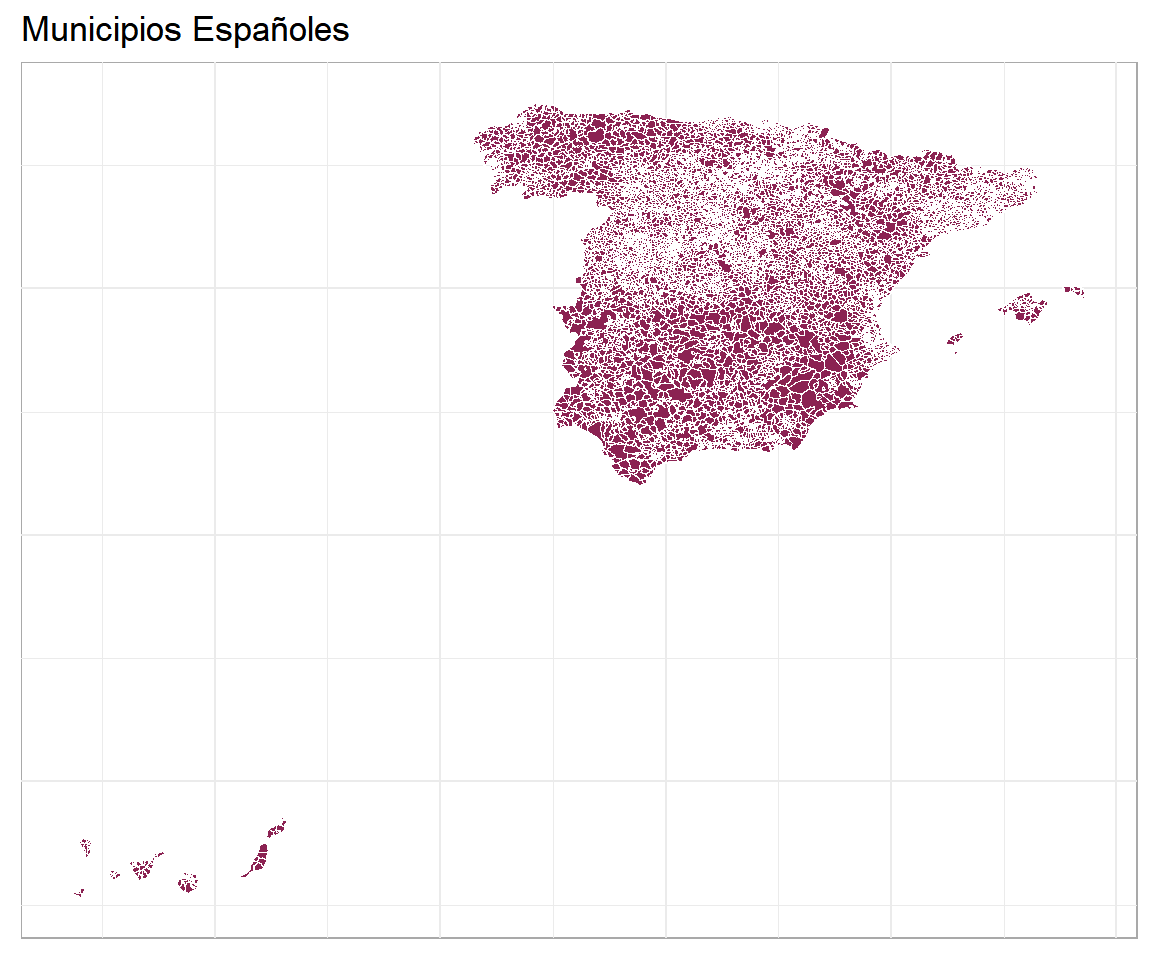
Mapa del porcentaje de Riesgo de Pobreza por Comunidad Autónoma
A modo de ejemplo vamos a representar el porcentaje de Riesgo de Pobreza por Comunidad Autónoma en un mapa. Los datos, referentes al año 2017, los obtenemos del Instituto Nacional de Estadística.
setwd("C:/Users/Usuario/Desktop/r_que_r/r_que_r/content/datasets")
library(readxl)
riesgo_pobreza <- read_excel("riesgo_pobreza.xls")
head(riesgo_pobreza, n=20)
## # A tibble: 19 x 3
## id Region Riesgo_pobreza
## <dbl> <chr> <dbl>
## 1 0 Andalucía 32
## 2 1 Aragón 14.2
## 3 2 Principado de Asturias 14
## 4 3 Balears, Illes 15.4
## 5 4 Canarias 32.1
## 6 5 Cantabria 19.9
## 7 6 Castilla y León 16.1
## 8 7 Castilla - La Mancha 29.9
## 9 8 Cataluña 13.6
## 10 9 Comunitat Valenciana 26
## 11 10 Extremadura 37.6
## 12 11 Galicia 18.8
## 13 12 Comunidad de Madrid 16.1
## 14 13 Región de Murcia 28.6
## 15 14 Comunidad Foral de Navarra 8.9
## 16 15 País Vasco 8.6
## 17 16 La Rioja 16.6
## 18 17 Ceuta 38.3
## 19 18 Melilla 21.4
Utilizamos la función left_join() para combinar el nuevo dataframe (riesgo_pobreza) con el que utilizamos previamente para realizar el mapa base (data_ccaa_mapa).
riesgo_pobreza$id <- as.character(riesgo_pobreza$id)
riesgo_pobreza_grafico <- data_ccaa_mapa %>%
left_join(riesgo_pobreza, by= "id")
head(riesgo_pobreza_grafico)
## # A tibble: 6 x 10
## long lat order hole piece group id shapefile_ccaa.~ Region
## <dbl> <dbl> <int> <lgl> <chr> <chr> <chr> <fct> <chr>
## 1 3.23e5 4.29e6 1 FALSE 1 0.1 0 AndalucÃa Andal~
## 2 3.23e5 4.29e6 2 FALSE 1 0.1 0 AndalucÃa Andal~
## 3 3.24e5 4.29e6 3 FALSE 1 0.1 0 AndalucÃa Andal~
## 4 3.25e5 4.29e6 4 FALSE 1 0.1 0 AndalucÃa Andal~
## 5 3.25e5 4.29e6 5 FALSE 1 0.1 0 AndalucÃa Andal~
## 6 3.26e5 4.29e6 6 FALSE 1 0.1 0 AndalucÃa Andal~
## # ... with 1 more variable: Riesgo_pobreza <dbl>
Por último realizamos el gráfico utilizando ggplot2 como hemos hecho previamente. Como ya se ha expuesto, podemos customizar nuestro grafico utilizando las funciones de dicho paquete. En el siguiente mapa realizamos algunas modificaciones (color de fondo, tamaño del texto del título, subtítulo, leyenda, cambio en la posición de la leyenda, etc.) sobre el mapa previo para ejemplificar la forma en la que podemos aplicar dichas modificaciones a nuestro gusto.
riesgo_pobreza_grafico %>%
ggplot(aes(x=long, y= lat, group = group)) +
geom_polygon(aes(fill=Riesgo_pobreza), color= "white", size = 0.2) +
labs( title = "Tasa de Riesgo de Pobreza por Comunidades Autónomas",
subtitle = "Unidades: Porcentaje",
caption = "Fuente: INE",
fill = "Tasa (%)") +
theme_minimal() +
theme(
axis.line = element_blank(),
axis.text = element_blank(),
axis.title = element_blank(),
axis.ticks = element_blank(),
plot.background = element_rect(fill = "snow", color = NA),
panel.background = element_rect(fill= "snow", color = NA),
plot.title = element_text(size = 16, hjust = 0),
plot.subtitle = element_text(size = 12, hjust = 0),
plot.caption = element_text(size = 8, hjust = 1),
legend.title = element_text(color = "grey40", size = 8),
legend.text = element_text(color = "grey40", size = 7, hjust = 0),
legend.position = c(0.93, 0.3),
plot.margin = unit(c(0.5,2,0.5,1), "cm"))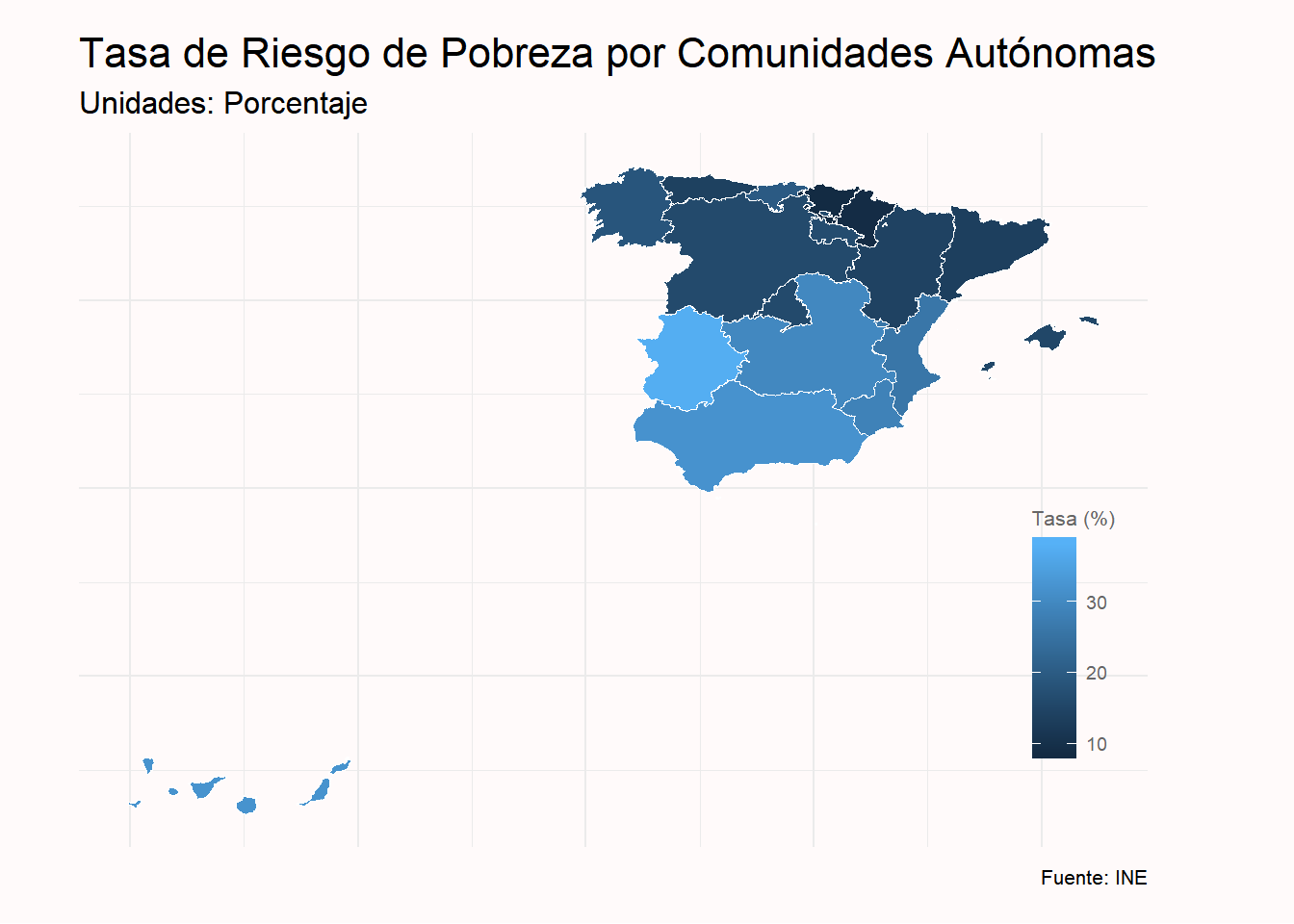
Como utilizamos valores continuos R utiliza un rango de colores azules para su representación gráfica. No obstante, nos puede interesar establecer grupos o categorías de valores para su representación. En este caso podemos calcular, por ejemplo, los quintiles de los nuestros valores y asignarles una categoría.
quantile(riesgo_pobreza_grafico$Riesgo_pobreza, probs = c(0.2, 0.4, 0.6, 0.8))
## 20% 40% 60% 80%
## 14.2 16.1 18.8 32.0
# En función de los resultados obtenidos establecemos nuestros cortes en los siguientes valores:
corte <- c(12, 18, 24, 30)
# Los valores mínimo y máximo son:
val_min <- min(riesgo_pobreza_grafico$Riesgo_pobreza)
val_max <- max(riesgo_pobreza_grafico$Riesgo_pobreza)
# Y por tanto, los rangos serán los siguientes:
breaks <- c(val_min, corte, val_max)
riesgo_pobreza_grafico$breaks <- cut(riesgo_pobreza_grafico$Riesgo_pobreza,
breaks = breaks,
include.lowest = T)
breaks_scale <- levels(riesgo_pobreza_grafico$breaks)
labels_scale <- rev(breaks_scale)
Con respecto a los colores a utilizar podemos indicar los colores de nuestra elección, como ya hemos realizado en algún post anterior, o podemos hacer uso de alguna paleta de colores existente. Un ejemplo de posibles paletas se encuentra en el paquete wesanderson, las cuales se pueden visualizar aquí. Para ello cargamos la librería y guardamos una de las paletas (Darjeeling1).
library(wesanderson)
## Warning: package 'wesanderson' was built under R version 3.6.1
colores <- wes_palette("Darjeeling1", 5, type = "discrete")
Por último realizamos el gráfico indicando los cortes (rangos) que nos interesan y los colores para cada una de las categorías de la siguiente manera:
riesgo_pobreza_grafico %>%
ggplot(aes(x=long, y= lat, group = group)) +
geom_polygon(aes(fill=breaks), color= "white", size = 0.2) +
labs( title = "Tasa de Riesgo de Pobreza por Comunidades Autónomas",
subtitle = "Unidades: Porcentaje",
caption = "Fuente: INE",
fill = "Tasa (%)") +
theme_minimal() +
theme(
axis.line = element_blank(),
axis.text = element_blank(),
axis.title = element_blank(),
axis.ticks = element_blank(),
plot.background = element_rect(fill = "snow", color = NA),
panel.background = element_rect(fill= "snow", color = NA),
plot.title = element_text(size = 16, hjust = 0),
plot.subtitle = element_text(size = 12, hjust = 0),
plot.caption = element_text(size = 8, hjust = 1),
legend.title = element_text(color = "grey40", size = 8),
legend.text = element_text(color = "grey40", size = 7, hjust = 0),
legend.position = c(0.93, 0.3),
plot.margin = unit(c(0.5,2,0.5,1), "cm")) +
scale_fill_manual(
values = rev(colores),
breaks = rev(breaks_scale))
En el último gráfico se visualiza claramente que las Comunidades Autónomas con menor tasa de riesgo de pobreza son el País Vasco y Navarra mientras que Extremadura, Andalucía y las Islas Canarias presentan los valores más elevados.
Mapa de la Tasa de Mortalidad por Provincia
En esta ocasión vamos a representar en un mapa la tasa de mortalidad (defunciones por mil habitantes) por provincia. Los datos, de nuevo, los obtenemos del Instituto Nacional de Estadística.
setwd("C:/Users/Usuario/Desktop/r_que_r/r_que_r/content/datasets")
tasa_mortalidad <- read_excel("tasa_mortalidad.xls")
head(tasa_mortalidad)
## # A tibble: 6 x 3
## id Provincia TM
## <dbl> <chr> <dbl>
## 1 0 Álava 8.46
## 2 1 Albacete 9.53
## 3 2 Alicante 8.81
## 4 3 Almería 7.78
## 5 4 Ávila 12.7
## 6 5 Badajoz 10.3
Utilizamos de nuevo la función left_join() para combinar el nuevo dataframe (tasa_mortalidad) con el que utilizamos previamente para realizar el mapa base (data_provincias_mapa).
tasa_mortalidad$id <- as.character(tasa_mortalidad$id)
tasa_mortalidad_grafico <- data_provincias_mapa %>%
left_join(tasa_mortalidad, by= "id")
head(tasa_mortalidad_grafico)
## # A tibble: 6 x 10
## long lat order hole piece group id shapefile_provin~ Provincia TM
## <dbl> <dbl> <int> <lgl> <chr> <chr> <chr> <fct> <chr> <dbl>
## 1 497824. 4.78e6 1 FALSE 1 0.1 0 "Ã\u0081lava" Álava 8.46
## 2 498457. 4.78e6 2 FALSE 1 0.1 0 "Ã\u0081lava" Álava 8.46
## 3 498532. 4.78e6 3 FALSE 1 0.1 0 "Ã\u0081lava" Álava 8.46
## 4 498382. 4.78e6 4 FALSE 1 0.1 0 "Ã\u0081lava" Álava 8.46
## 5 498946. 4.78e6 5 FALSE 1 0.1 0 "Ã\u0081lava" Álava 8.46
## 6 499046. 4.78e6 6 FALSE 1 0.1 0 "Ã\u0081lava" Álava 8.46
Por último realizamos el gráfico con ggplot usando el mismo theme que el utilizado en el mapa de las Comunidades Autónomas. Sin embargo, en esta ocasión, cambiamos la paleta de colores utilizando la función scale_fill_gradient() mediante la cual seleccionamos el color amarillo para los valores más bajos y el color rojo para los valores más altos.
tasa_mortalidad_grafico %>%
ggplot(aes(x=long, y= lat, group = group)) +
geom_polygon(aes(fill= TM), color= "white", size = 0.2) +
labs( title = "Tasa Bruta de Mortalidad por Provincia",
subtitle = "Defunciones por mil habitantes",
caption = "Fuente: INE",
fill = "") +
theme_minimal() +
theme(
axis.line = element_blank(),
axis.text = element_blank(),
axis.title = element_blank(),
axis.ticks = element_blank(),
plot.background = element_rect(fill = "snow", color = NA),
panel.background = element_rect(fill= "snow", color = NA),
plot.title = element_text(size = 16, hjust = 0),
plot.subtitle = element_text(size = 12, hjust = 0),
plot.caption = element_text(size = 8, hjust = 1),
legend.title = element_text(color = "grey40", size = 8),
legend.text = element_text(color = "grey40", size = 7, hjust = 0),
legend.position = c(0.93, 0.3),
plot.margin = unit(c(0.5,2,0.5,1), "cm")) +
scale_fill_gradient(low = "yellow", high = "red")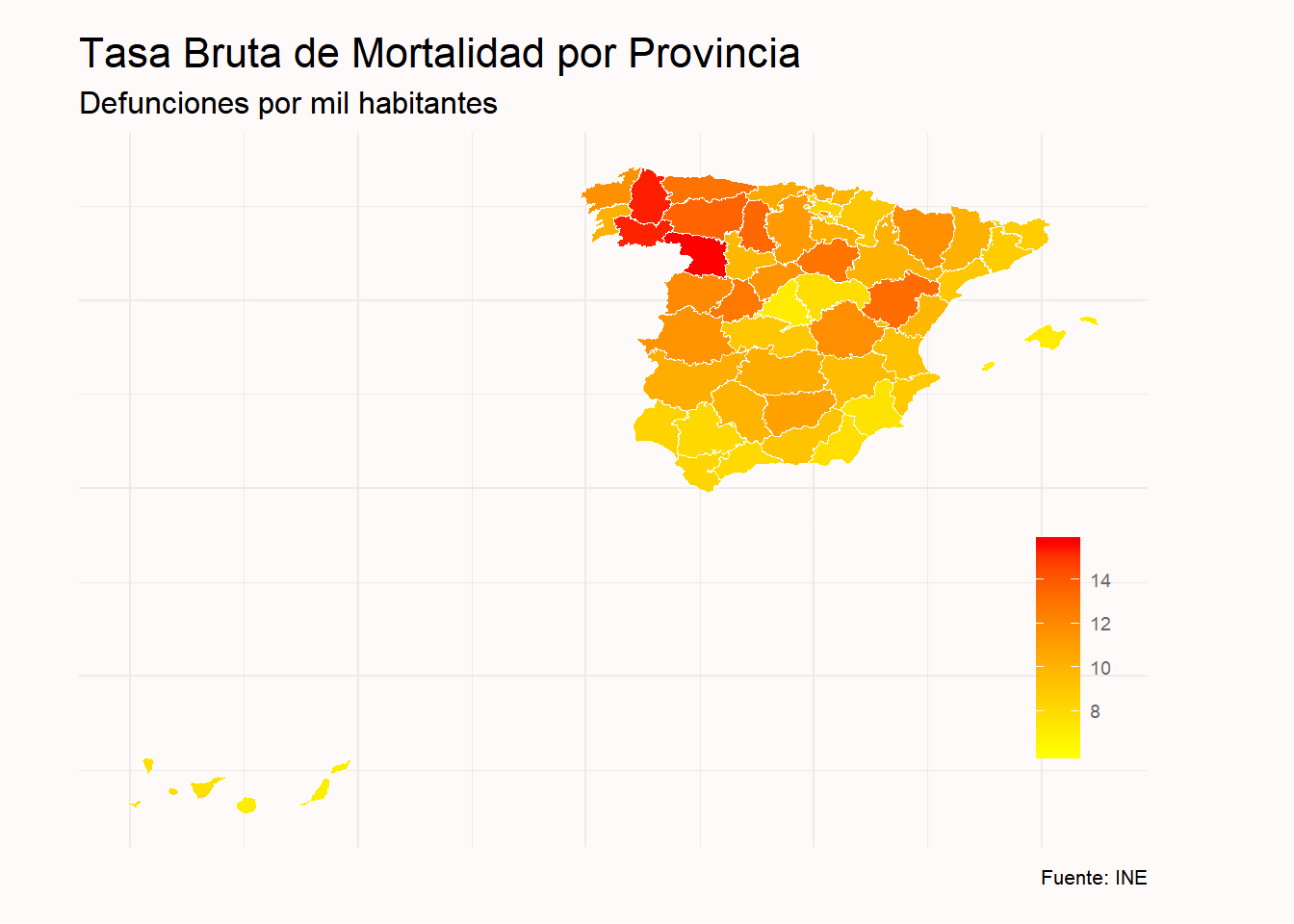
Para establecer grupos o categorías de valores como la realizada para las Comunidades Autónomas realizaremos una operativa similar a la realizada previamente. En primer lugar identificaremos los cortes el valor mínimo y máximo del rango.
quantile(tasa_mortalidad_grafico$TM, probs = c(0.2, 0.4, 0.6, 0.8))
## 20% 40% 60% 80%
## 8.07 9.13 10.26 11.70
# En función de los resultados obtenidos establecemos nuestros cortes en los siguientes valores:
corte <- c(8, 9.5, 10.5, 12)
# Los valores mínimo y máximo son:
val_min <- min(tasa_mortalidad_grafico$TM)
val_max <- max(tasa_mortalidad_grafico$TM)
# Y por tanto, los rangos serán los siguientes:
breaks <- c(val_min, corte, val_max)
tasa_mortalidad_grafico$breaks <- cut(tasa_mortalidad_grafico$TM,
breaks = breaks,
include.lowest = T)
breaks_scale <- levels(tasa_mortalidad_grafico$breaks)
labels_scale <- rev(breaks_scale)
Por último realizamos el gráfico indicando los cortes (rangos) establecidos y los colores para cada una de las categorías. En esta ocasión cargamos una nueva paleta (Moonrise3) de la misma librería usada en previamente.
colores <- wes_palette("Moonrise3", 5, type = "discrete")
tasa_mortalidad_grafico %>%
ggplot(aes(x=long, y= lat, group = group)) +
geom_polygon(aes(fill=breaks), color= "white", size = 0.2) +
labs( title = "Tasa Bruta de Mortalidad por Provincia",
subtitle = "Defunciones por mil habitantes",
caption = "Fuente: INE",
fill = "") +
theme_minimal() +
theme(
axis.line = element_blank(),
axis.text = element_blank(),
axis.title = element_blank(),
axis.ticks = element_blank(),
plot.background = element_rect(fill = "snow", color = NA),
panel.background = element_rect(fill= "snow", color = NA),
plot.title = element_text(size = 16, hjust = 0),
plot.subtitle = element_text(size = 12, hjust = 0),
plot.caption = element_text(size = 8, hjust = 1),
legend.title = element_text(color = "grey40", size = 8),
legend.text = element_text(color = "grey40", size = 7, hjust = 0),
legend.position = c(0.93, 0.3),
plot.margin = unit(c(0.5,2,0.5,1), "cm")) +
scale_fill_manual(
values = rev(colores),
breaks = rev(breaks_scale))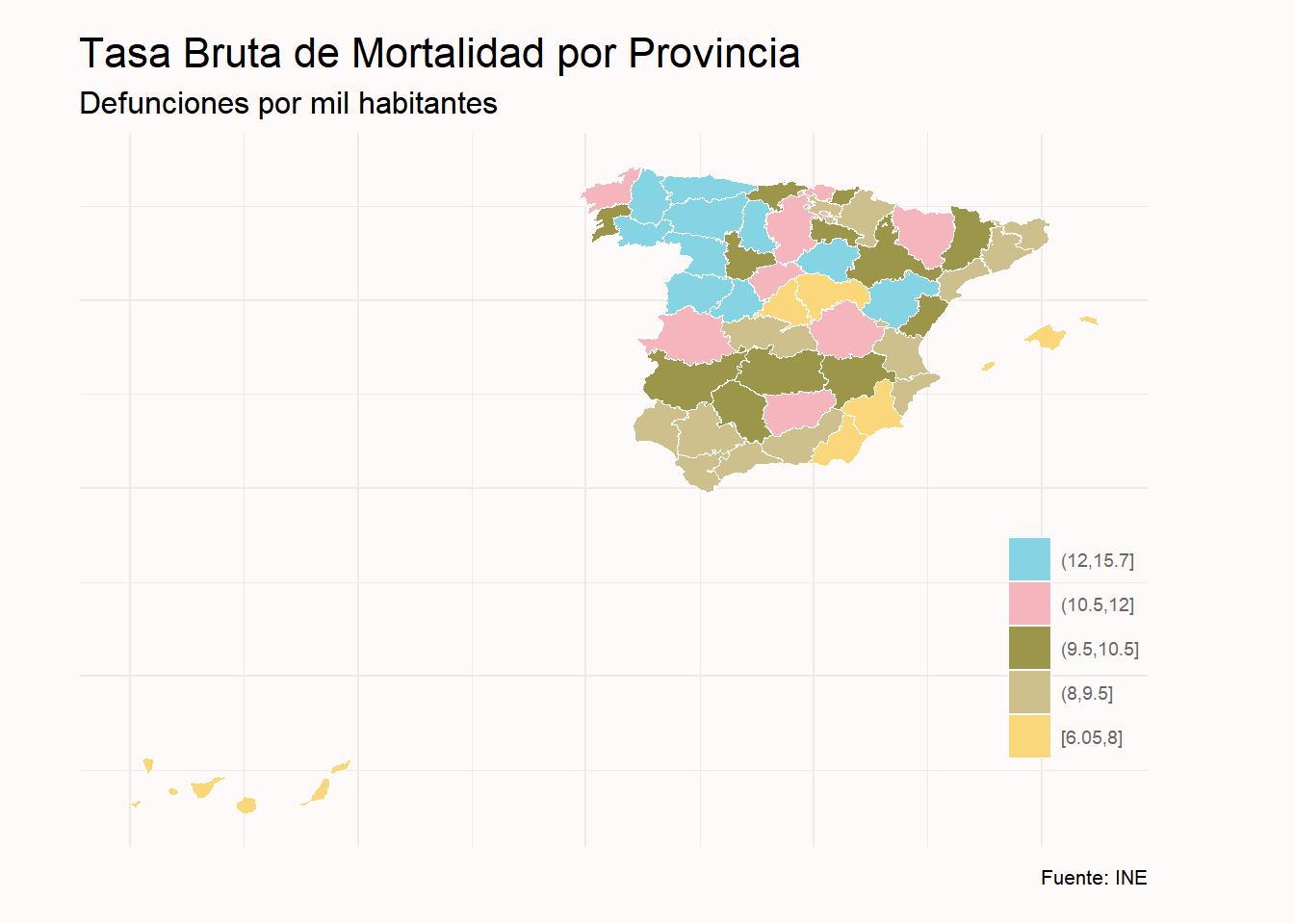
Mapa de la Renta Media por Persona por Municipios Españoles
Por último vamos a realizar un mapa a nivel de Municipios donde se exponga la Renta Media por Persona en el año 2016, según los datos obtenidos del INE.
En primer lugar, haciendo uso de los códigos de los municipios que se pueden consultar en el INE, vamos a comprobar, de forma aleatoria, la existencia de algunos de ellos utilizando el dataset utilizado previamente (data_municipios_mapa) y los representaremos gráficamente:
data_municipios_mapa$codigo_ine <- as.numeric(data_municipios_mapa$codigo_ine)
# Probando Abengibre (02001) en la Provincia de Albacete (2)
prueba <- data_municipios_mapa %>%
filter(codigo_ine == 22001)
prueba %>%
ggplot() +
geom_polygon(aes( x= long, y = lat, group = group),
fill = "blueviolet",
color = "white",
size = 0.1) +
theme_minimal()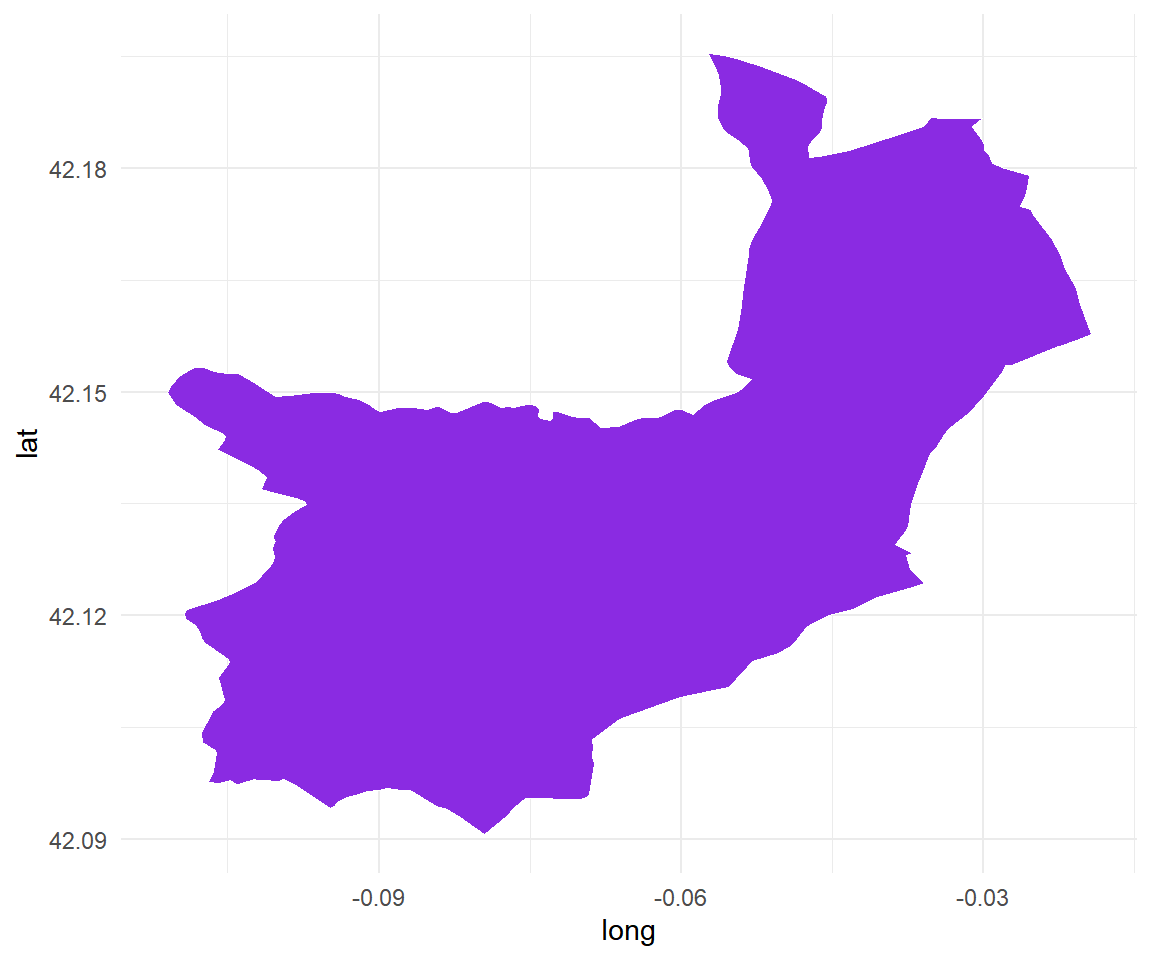
# Probando Agost (03002) en la Provincia de Alicante (3)
prueba <- data_municipios_mapa %>%
filter(codigo_ine == 03002)
prueba %>%
ggplot() +
geom_polygon(aes( x= long, y = lat, group = group),
fill = "blueviolet",
color = "white",
size = 0.1) +
theme_minimal()
# Probando Allande (33001) en la Provincia de Asturias (33)
prueba <- data_municipios_mapa %>%
filter(codigo_ine == 33001)
prueba %>%
ggplot() +
geom_polygon(aes( x= long, y = lat, group = group),
fill = "blueviolet",
color = "white",
size = 0.1) +
theme_minimal()
En segundo lugar cargamos el archivo donde se encuentra la información de la Renta Media (por persona) en cada Municipio.
setwd("C:/Users/Usuario/Desktop/r_que_r/r_que_r/content/datasets")
renta_media <- read_excel("renta_media.xls")
head(renta_media)
## # A tibble: 6 x 3
## Provincia Municipio renta_media
## <chr> <chr> <chr>
## 1 Albacete 02001 Abengibre 9690
## 2 Albacete 02002 Alatoz 8008
## 3 Albacete 02003 Albacete 10795
## 4 Albacete 02004 Albatana 8082
## 5 Albacete 02005 Alborea 7573
## 6 Albacete 02006 Alcadozo 8100
En el dataframe el nombre del código y del municipio aparecen en la misma columna (Municipio). Para separar ambos conceptos en dos columnas utilizamos la función separate().
renta_media_separado <- renta_media %>%
separate(Municipio, c("cod", "municipio"),
sep = " ",
extra = "merge")
head(renta_media_separado)
## # A tibble: 6 x 4
## Provincia cod municipio renta_media
## <chr> <chr> <chr> <chr>
## 1 Albacete 02001 Abengibre 9690
## 2 Albacete 02002 Alatoz 8008
## 3 Albacete 02003 Albacete 10795
## 4 Albacete 02004 Albatana 8082
## 5 Albacete 02005 Alborea 7573
## 6 Albacete 02006 Alcadozo 8100
# Nombramos la columna codigo_ine
renta_media_separado$codigo_ine <- as.numeric(renta_media_separado$cod)
head(renta_media_separado)
## # A tibble: 6 x 5
## Provincia cod municipio renta_media codigo_ine
## <chr> <chr> <chr> <chr> <dbl>
## 1 Albacete 02001 Abengibre 9690 2001
## 2 Albacete 02002 Alatoz 8008 2002
## 3 Albacete 02003 Albacete 10795 2003
## 4 Albacete 02004 Albatana 8082 2004
## 5 Albacete 02005 Alborea 7573 2005
## 6 Albacete 02006 Alcadozo 8100 2006
Unimos los dos dataframes usando left_join().
renta_media_grafico <- data_municipios_mapa %>%
left_join(renta_media_separado, by = "codigo_ine")
Antes de realizar el mapa general vamos a visualizar previamente algunas provincias, también seleccionadas de forma aleatoria, con el objetivo de representar graficamente los distintos municipios de cada una de ellas atendiendo a su Renta Media. Aprovechamos este ejercicio para utilizar diferentes opciones para seleccionar colores a la hora de representar los municipios. Nótese que los municipios coloreados en gris son aquellos en los que el INE no provee información sobre la Renta Media.
# Provincia de Castellón
renta_media_grafico %>%
filter(Provincia =="Castellón") %>%
ggplot(aes(x=long, y= lat, group = group)) +
geom_polygon(aes(fill= as.double(renta_media)), color= "white", size = 0.1) +
labs( title = "Castellón",
subtitle = "Renta Media por Persona en 2016",
caption = "Fuente: INE",
fill = "") +
theme_minimal() +
theme(
axis.line = element_blank(),
axis.text = element_blank(),
axis.title = element_blank(),
axis.ticks = element_blank(),
plot.background = element_rect(fill = "snow", color = NA),
panel.background = element_rect(fill= "snow", color = NA),
plot.title = element_text(size = 16, hjust = 0),
plot.subtitle = element_text(size = 12, hjust = 0),
plot.caption = element_text(size = 8, hjust = 1),
legend.title = element_text(color = "grey40", size = 8),
legend.text = element_text(color = "grey40", size = 7, hjust = 0),
legend.position = c(0.93, 0.3),
plot.margin = unit(c(0.5,2,0.5,1), "cm")) 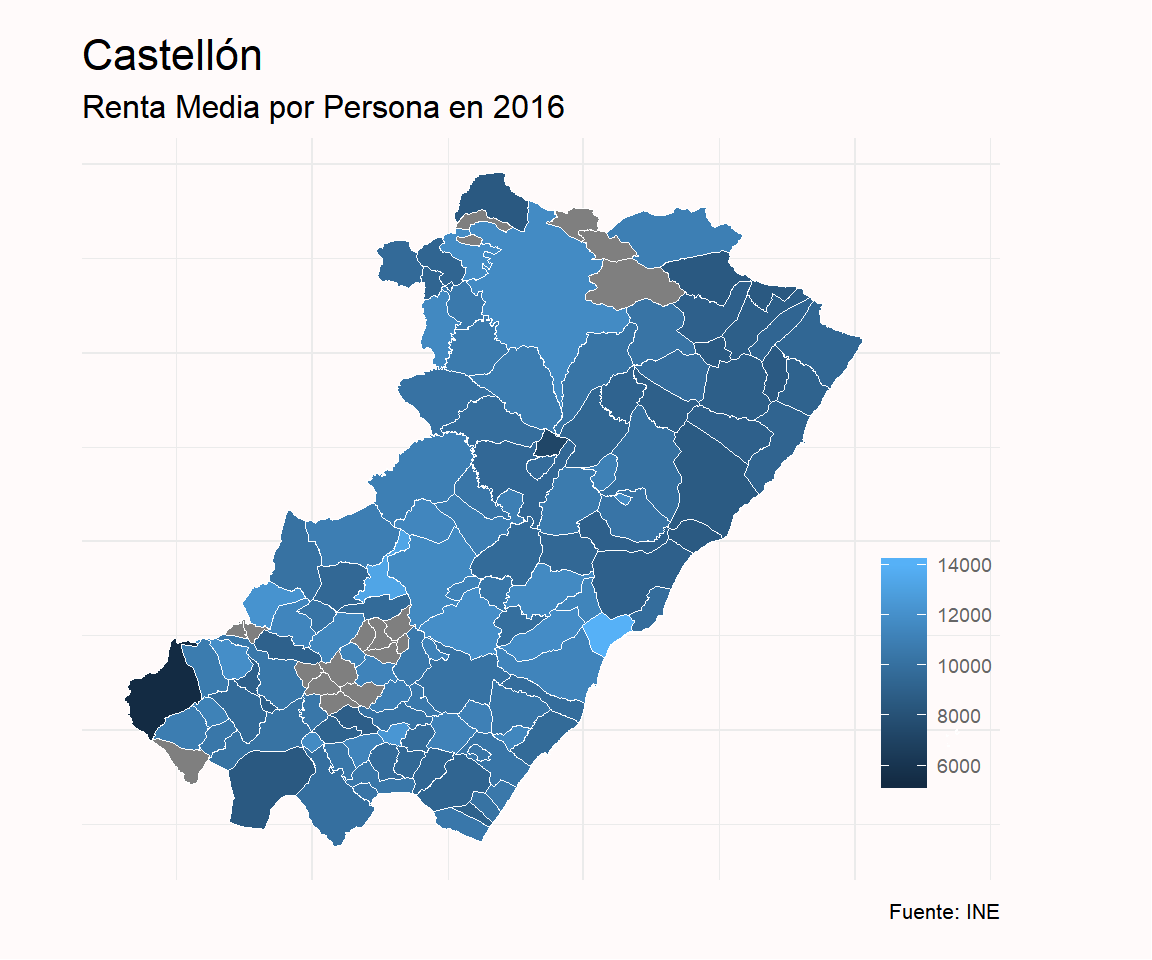
# Provincia de Gipuzkoa
renta_media_grafico %>%
filter(Provincia =="Guipozkoa") %>%
ggplot(aes(x=long, y= lat, group = group)) +
geom_polygon(aes(fill= as.double(renta_media)), color= "white", size = 0.1) +
labs( title = "Gipuzkoa",
subtitle = "Renta Media por Persona en 2016",
caption = "Fuente: INE",
fill = "") +
theme_minimal() +
theme(
axis.line = element_blank(),
axis.text = element_blank(),
axis.title = element_blank(),
axis.ticks = element_blank(),
plot.background = element_rect(fill = "snow", color = NA),
panel.background = element_rect(fill= "snow", color = NA),
plot.title = element_text(size = 16, hjust = 0),
plot.subtitle = element_text(size = 12, hjust = 0),
plot.caption = element_text(size = 8, hjust = 1),
legend.title = element_text(color = "grey40", size = 8),
legend.text = element_text(color = "grey40", size = 7, hjust = 0),
legend.position = c(0.93, 0.3),
plot.margin = unit(c(0.5,2,0.5,1), "cm")) +
scale_fill_gradient(low = "red", high = "green")
# Provincia de Zaragoza
renta_media_grafico %>%
filter(Provincia =="Zaragoza") %>%
ggplot(aes(x=long, y= lat, group = group)) +
geom_polygon(aes(fill= as.double(renta_media)), color= "white", size = 0.1) +
labs( title = "Zaragoza",
subtitle = "Renta Media por Persona en 2016",
caption = "Fuente: INE",
fill = "") +
theme_minimal() +
theme(
axis.line = element_blank(),
axis.text = element_blank(),
axis.title = element_blank(),
axis.ticks = element_blank(),
plot.background = element_rect(fill = "snow", color = NA),
panel.background = element_rect(fill= "snow", color = NA),
plot.title = element_text(size = 16, hjust = 0),
plot.subtitle = element_text(size = 12, hjust = 0),
plot.caption = element_text(size = 8, hjust = 1),
legend.title = element_text(color = "grey40", size = 8),
legend.text = element_text(color = "grey40", size = 7, hjust = 0),
legend.position = c(0.93, 0.8),
plot.margin = unit(c(0.5,2,0.5,1), "cm")) +
scale_fill_gradientn(colours= terrain.colors(10))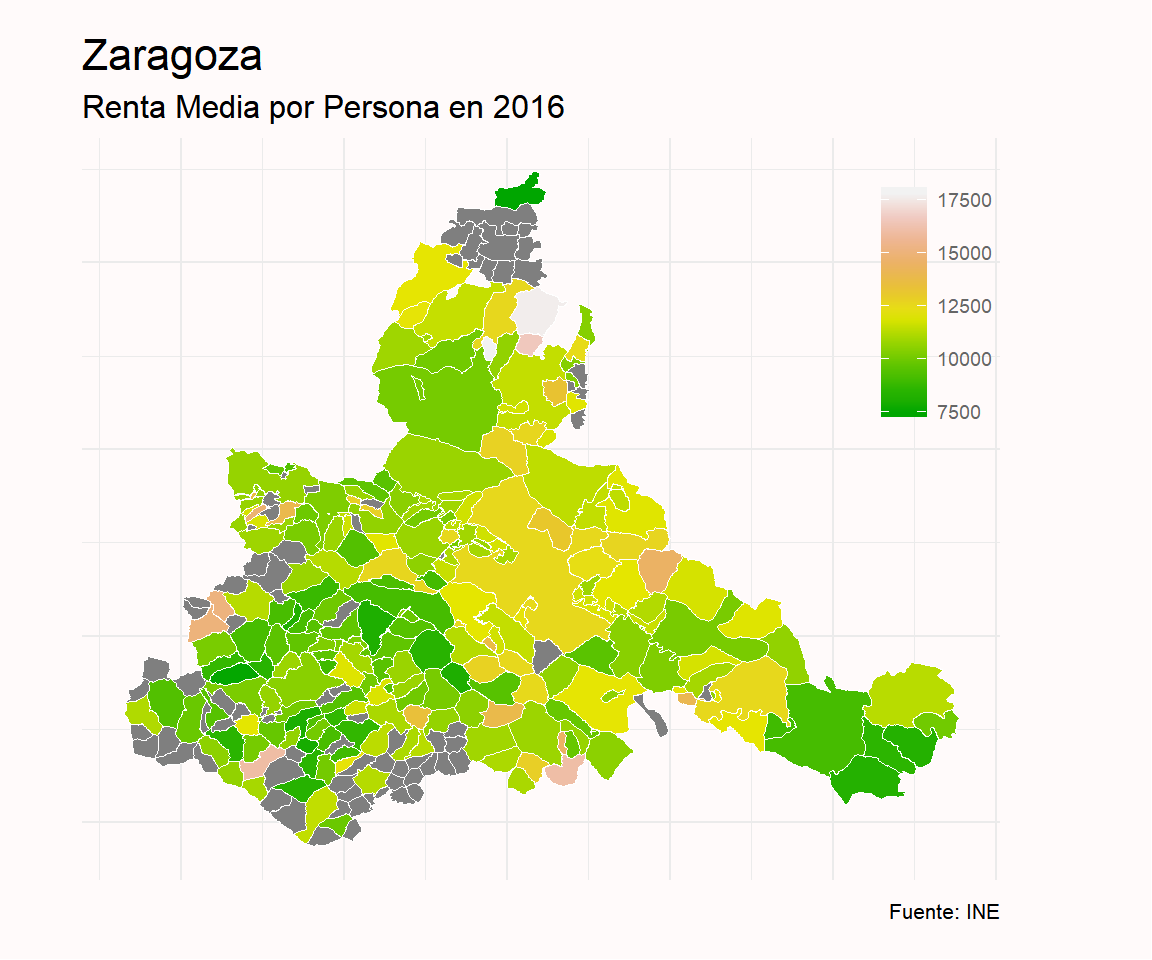
# Provincia de Valencia
renta_media_grafico %>%
filter(Provincia =="Valencia") %>%
ggplot(aes(x=long, y= lat, group = group)) +
geom_polygon(aes(fill= as.double(renta_media)), color= "white", size = 0.1) +
labs( title = "Valencia",
subtitle = "Renta Media por Persona en 2016",
caption = "Fuente: INE",
fill = "") +
theme_minimal() +
theme(
axis.line = element_blank(),
axis.text = element_blank(),
axis.title = element_blank(),
axis.ticks = element_blank(),
plot.background = element_rect(fill = "snow", color = NA),
panel.background = element_rect(fill= "snow", color = NA),
plot.title = element_text(size = 16, hjust = 0),
plot.subtitle = element_text(size = 12, hjust = 0),
plot.caption = element_text(size = 8, hjust = 1),
legend.title = element_text(color = "grey40", size = 8),
legend.text = element_text(color = "grey40", size = 7, hjust = 0),
legend.position = c(0.93, 0.8),
plot.margin = unit(c(0.5,2,0.5,1), "cm")) +
scale_fill_gradientn(colours= rainbow(4))
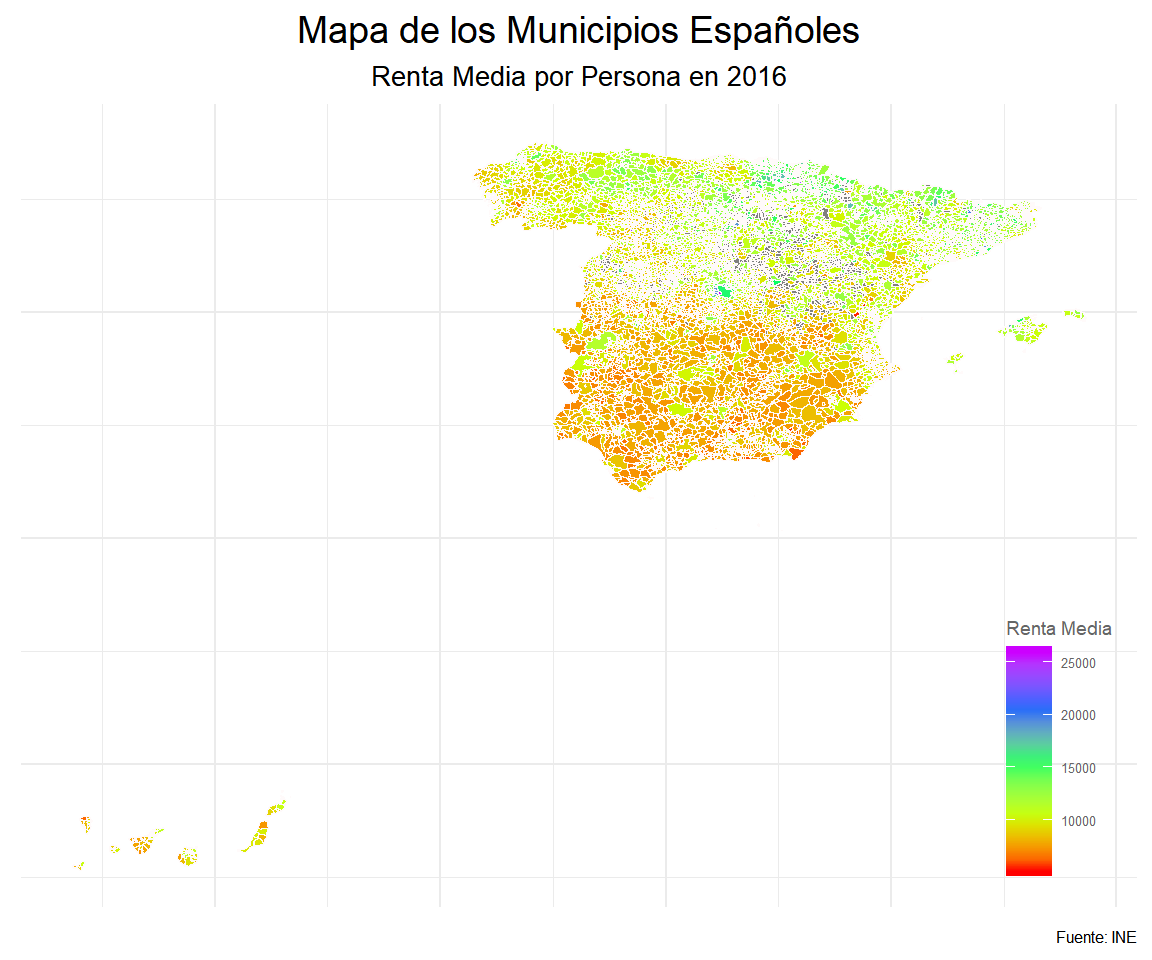
Para finalizar realizamos el mapa general donde representaremos el conjunto de Municipios Españoles según su Renta Media por persona. Sin entrar en detalle, siendo posible identificar diversas dinámicas, en términos generales el mapa refleja claramente la notable diferencia existente entre el norte y el sur del país en términos de Renta Media.
renta_media_grafico %>%
ggplot(aes(x = long, y = lat, group = group)) +
geom_polygon(aes(fill = as.numeric(renta_media)),
color = "snow",
size = 0.001) +
labs( title = "Mapa de los Municipios Españoles",
subtitle = "Renta Media por Persona en 2016",
caption = "Fuente: INE",
fill = "Renta Media") +
theme_minimal() +
theme(
axis.line = element_blank(),
axis.text = element_blank(),
axis.title = element_blank(),
axis.ticks = element_blank(),
plot.background = element_blank(),
panel.background = element_blank(),
plot.title = element_text(size = 14, hjust = 0.5),
plot.subtitle = element_text(size = 10, hjust = 0.5),
plot.caption = element_text(size = 6, hjust = 1),
legend.title = element_text(color = "grey40", size = 7),
legend.text = element_text(color = "grey40", size = 5, hjust = 0),
legend.position = c(0.93, 0.2)) +
scale_fill_gradientn(colours= rainbow(5))