Introducción
Esta semana el proyecto TidyTuesday comparte un dataset con información (id, nombre, nacionalidad, nombre de la misión, entre otras) sobre astronautas que han participado en misiones espaciales antes del 15 de enero de 2020. En los links señalados se puede consultar información sobre el proyecto Tidytuesday y sobre el dataset en cuestión (también sobre sus autores).
paquetes y dataset
library(readr)
library(tidyverse)
library(stringr)
library(png)
library(ggpubr)
library(gganimate)
library(Hmisc)
library(DT)
astronauts <- read_csv('https://raw.githubusercontent.com/rfordatascience/tidytuesday/master/data/2020/2020-07-14/astronauts.csv')
## Parsed with column specification:
## cols(
## .default = col_double(),
## name = col_character(),
## original_name = col_character(),
## sex = col_character(),
## nationality = col_character(),
## military_civilian = col_character(),
## selection = col_character(),
## occupation = col_character(),
## mission_title = col_character(),
## ascend_shuttle = col_character(),
## in_orbit = col_character(),
## descend_shuttle = col_character()
## )
## See spec(...) for full column specifications.
Examinemos el dataset
En primer lugar voy a examinar rápidamente el dataset descargado (astronauts).
Nombres de las columnas:
colnames(astronauts)
## [1] "id" "number"
## [3] "nationwide_number" "name"
## [5] "original_name" "sex"
## [7] "year_of_birth" "nationality"
## [9] "military_civilian" "selection"
## [11] "year_of_selection" "mission_number"
## [13] "total_number_of_missions" "occupation"
## [15] "year_of_mission" "mission_title"
## [17] "ascend_shuttle" "in_orbit"
## [19] "descend_shuttle" "hours_mission"
## [21] "total_hrs_sum" "field21"
## [23] "eva_hrs_mission" "total_eva_hrs"
Primeras 10 observaciones:
head(astronauts, n= 10)
## # A tibble: 10 x 24
## id number nationwide_numb~ name original_name sex year_of_birth
## <dbl> <dbl> <dbl> <chr> <chr> <chr> <dbl>
## 1 1 1 1 Gaga~ <U+0413><U+0410><U+0413><U+0410><U+0420><U+0418><U+041D> <U+042E><U+0440><U+0438><U+0439>~ male 1934
## 2 2 2 2 Tito~ <U+0422><U+0418><U+0422><U+041E><U+0412> <U+0413><U+0435><U+0440><U+043C><U+0430><U+043D>~ male 1935
## 3 3 3 1 Glen~ Glenn, John ~ male 1921
## 4 4 3 1 Glen~ Glenn, John ~ male 1921
## 5 5 4 2 Carp~ Carpenter, M~ male 1925
## 6 6 5 2 Niko~ <U+041D><U+0418><U+041A><U+041E><U+041B><U+0410><U+0415><U+0412> <U+0410><U+043D><U+0434>~ male 1929
## 7 7 5 2 Niko~ <U+041D><U+0418><U+041A><U+041E><U+041B><U+0410><U+0415><U+0412> <U+0410><U+043D><U+0434>~ male 1929
## 8 8 6 4 Popo~ <U+041F><U+041E><U+041F><U+041E><U+0412><U+0418><U+0427> <U+041F><U+0430><U+0432><U+0435>~ male 1930
## 9 9 6 4 Popo~ <U+041F><U+041E><U+041F><U+041E><U+0412><U+0418><U+0427> <U+041F><U+0430><U+0432><U+0435>~ male 1930
## 10 10 7 3 Schi~ Schirra, Wal~ male 1923
## # ... with 17 more variables: nationality <chr>, military_civilian <chr>,
## # selection <chr>, year_of_selection <dbl>, mission_number <dbl>,
## # total_number_of_missions <dbl>, occupation <chr>, year_of_mission <dbl>,
## # mission_title <chr>, ascend_shuttle <chr>, in_orbit <chr>,
## # descend_shuttle <chr>, hours_mission <dbl>, total_hrs_sum <dbl>,
## # field21 <dbl>, eva_hrs_mission <dbl>, total_eva_hrs <dbl>
Estructura:
str(astronauts)
## tibble [1,277 x 24] (S3: spec_tbl_df/tbl_df/tbl/data.frame)
## $ id : num [1:1277] 1 2 3 4 5 6 7 8 9 10 ...
## $ number : num [1:1277] 1 2 3 3 4 5 5 6 6 7 ...
## $ nationwide_number : num [1:1277] 1 2 1 1 2 2 2 4 4 3 ...
## $ name : chr [1:1277] "Gagarin, Yuri" "Titov, Gherman" "Glenn, John H., Jr." "Glenn, John H., Jr." ...
## $ original_name : chr [1:1277] "<U+0413><U+0410><U+0413><U+0410><U+0420><U+0418><U+041D> <U+042E><U+0440><U+0438><U+0439> <U+0410><U+043B><U+04"| __truncated__ "<U+0422><U+0418><U+0422><U+041E><U+0412> <U+0413><U+0435><U+0440><U+043C><U+0430><U+043D> <U+0421><U+0442><U+04"| __truncated__ "Glenn, John H., Jr." "Glenn, John H., Jr." ...
## $ sex : chr [1:1277] "male" "male" "male" "male" ...
## $ year_of_birth : num [1:1277] 1934 1935 1921 1921 1925 ...
## $ nationality : chr [1:1277] "U.S.S.R/Russia" "U.S.S.R/Russia" "U.S." "U.S." ...
## $ military_civilian : chr [1:1277] "military" "military" "military" "military" ...
## $ selection : chr [1:1277] "TsPK-1" "TsPK-1" "NASA Astronaut Group 1" "NASA Astronaut Group 2" ...
## $ year_of_selection : num [1:1277] 1960 1960 1959 1959 1959 ...
## $ mission_number : num [1:1277] 1 1 1 2 1 1 2 1 2 1 ...
## $ total_number_of_missions: num [1:1277] 1 1 2 2 1 2 2 2 2 3 ...
## $ occupation : chr [1:1277] "pilot" "pilot" "pilot" "PSP" ...
## $ year_of_mission : num [1:1277] 1961 1961 1962 1998 1962 ...
## $ mission_title : chr [1:1277] "Vostok 1" "Vostok 2" "MA-6" "STS-95" ...
## $ ascend_shuttle : chr [1:1277] "Vostok 1" "Vostok 2" "MA-6" "STS-95" ...
## $ in_orbit : chr [1:1277] "Vostok 2" "Vostok 2" "MA-6" "STS-95" ...
## $ descend_shuttle : chr [1:1277] "Vostok 3" "Vostok 2" "MA-6" "STS-95" ...
## $ hours_mission : num [1:1277] 1.77 25 5 213 5 ...
## $ total_hrs_sum : num [1:1277] 1.77 25.3 218 218 5 ...
## $ field21 : num [1:1277] 0 0 0 0 0 0 0 0 0 0 ...
## $ eva_hrs_mission : num [1:1277] 0 0 0 0 0 0 0 0 0 0 ...
## $ total_eva_hrs : num [1:1277] 0 0 0 0 0 0 0 0 0 0 ...
## - attr(*, "spec")=
## .. cols(
## .. id = col_double(),
## .. number = col_double(),
## .. nationwide_number = col_double(),
## .. name = col_character(),
## .. original_name = col_character(),
## .. sex = col_character(),
## .. year_of_birth = col_double(),
## .. nationality = col_character(),
## .. military_civilian = col_character(),
## .. selection = col_character(),
## .. year_of_selection = col_double(),
## .. mission_number = col_double(),
## .. total_number_of_missions = col_double(),
## .. occupation = col_character(),
## .. year_of_mission = col_double(),
## .. mission_title = col_character(),
## .. ascend_shuttle = col_character(),
## .. in_orbit = col_character(),
## .. descend_shuttle = col_character(),
## .. hours_mission = col_double(),
## .. total_hrs_sum = col_double(),
## .. field21 = col_double(),
## .. eva_hrs_mission = col_double(),
## .. total_eva_hrs = col_double()
## .. )
¿Hay NA´s?:
sapply(astronauts, function(x)
sum(is.na(x))
)
## id number nationwide_number
## 0 0 0
## name original_name sex
## 0 5 0
## year_of_birth nationality military_civilian
## 0 0 0
## selection year_of_selection mission_number
## 1 0 0
## total_number_of_missions occupation year_of_mission
## 0 0 0
## mission_title ascend_shuttle in_orbit
## 1 1 0
## descend_shuttle hours_mission total_hrs_sum
## 1 0 0
## field21 eva_hrs_mission total_eva_hrs
## 0 0 0
Principales indicadores estadísticos:
summary(astronauts)
## id number nationwide_number name
## Min. : 1 Min. : 1.0 Min. : 1.0 Length:1277
## 1st Qu.: 320 1st Qu.:153.0 1st Qu.: 47.0 Class :character
## Median : 639 Median :278.0 Median :110.0 Mode :character
## Mean : 639 Mean :274.2 Mean :128.8
## 3rd Qu.: 958 3rd Qu.:390.0 3rd Qu.:204.0
## Max. :1277 Max. :565.0 Max. :433.0
## original_name sex year_of_birth nationality
## Length:1277 Length:1277 Min. :1921 Length:1277
## Class :character Class :character 1st Qu.:1944 Class :character
## Mode :character Mode :character Median :1952 Mode :character
## Mean :1952
## 3rd Qu.:1959
## Max. :1983
## military_civilian selection year_of_selection mission_number
## Length:1277 Length:1277 Min. :1959 Min. :1.000
## Class :character Class :character 1st Qu.:1978 1st Qu.:1.000
## Mode :character Mode :character Median :1987 Median :2.000
## Mean :1986 Mean :1.992
## 3rd Qu.:1995 3rd Qu.:3.000
## Max. :2018 Max. :7.000
## total_number_of_missions occupation year_of_mission mission_title
## Min. :1.000 Length:1277 Min. :1961 Length:1277
## 1st Qu.:2.000 Class :character 1st Qu.:1986 Class :character
## Median :3.000 Mode :character Median :1995 Mode :character
## Mean :2.983 Mean :1995
## 3rd Qu.:4.000 3rd Qu.:2003
## Max. :7.000 Max. :2019
## ascend_shuttle in_orbit descend_shuttle hours_mission
## Length:1277 Length:1277 Length:1277 Min. : 0
## Class :character Class :character Class :character 1st Qu.: 190
## Mode :character Mode :character Mode :character Median : 261
## Mean : 1051
## 3rd Qu.: 382
## Max. :10505
## total_hrs_sum field21 eva_hrs_mission total_eva_hrs
## Min. : 0.61 Min. :0.0000 Min. : 0.000 Min. : 0.00
## 1st Qu.: 482.00 1st Qu.:0.0000 1st Qu.: 0.000 1st Qu.: 0.00
## Median : 932.00 Median :0.0000 Median : 0.000 Median : 0.00
## Mean : 2968.34 Mean :0.6288 Mean : 3.661 Mean :10.76
## 3rd Qu.: 4264.00 3rd Qu.:1.0000 3rd Qu.: 4.720 3rd Qu.:19.52
## Max. :21083.52 Max. :7.0000 Max. :89.130 Max. :78.80
¿Principales nacionalidades?:
astronauts %>%
count(nationality , sort = TRUE)
## # A tibble: 40 x 2
## nationality n
## <chr> <int>
## 1 U.S. 854
## 2 U.S.S.R/Russia 273
## 3 Japan 20
## 4 Canada 18
## 5 France 18
## 6 Germany 16
## 7 China 14
## 8 Italy 13
## 9 U.K./U.S. 6
## 10 Australia 4
## # ... with 30 more rows
¿Programas de selección de astronautas?:
astronauts %>%
count(selection, sort = TRUE)
## # A tibble: 230 x 2
## selection n
## <chr> <int>
## 1 NASA- 16 51
## 2 NASA- 12 39
## 3 NASA- 13 38
## 4 NASA- 8 38
## 5 NASA- 9 34
## 6 NASA- 10 32
## 7 NASA- 15 30
## 8 NASA- 14 28
## 9 NASA- 17 27
## 10 NASA- 18 26
## # ... with 220 more rows
¿Sexo y ocupación de los astronautas?:
astronauts %>%
count(sex, sort = TRUE)
## # A tibble: 2 x 2
## sex n
## <chr> <int>
## 1 male 1134
## 2 female 143
astronauts %>%
count(occupation, sort = TRUE)
## # A tibble: 12 x 2
## occupation n
## <chr> <int>
## 1 MSP 498
## 2 commander 315
## 3 pilot 196
## 4 flight engineer 192
## 5 PSP 59
## 6 Other (space tourist) 5
## 7 Flight engineer 4
## 8 Other (Space tourist) 3
## 9 Space tourist 2
## 10 Other (Journalist) 1
## 11 Pilot 1
## 12 spaceflight participant 1
Bueno bueno, parece interesante ¿no? Hay algunos aspectos que me han llamado la atención (de hecho uno de los grandes atractivos que destaco del proyecto Tidytuesday es precisamente eso, que a cada participante le llama la atención aspectos distintos del mismo dataset y luego lo ponen en valor y en conocimiento de la comunidad. Una verdadera joya este proyecto en el que me da pena no tener tiempo para participar tanto como me gustaría). El caso es que… hasta el momento han habido al menos ocho turistas espaciales! y un periodista espacial! Bastante curioso aunque con ello creo que no vamos a ir muy lejos en nuestro análisis.
Por otro lado, otro aspecto que destaca es que si tenemos en cuenta la nacionalidad de los astronautas el dataset parece indicar que entre Estados Unidos y Rusia (/USSR) anda el juego. Es bastante probable que la carrera espacial llevada a cabo entre EEUU y la Unión Soviética durante la guerra fría explique la alta participación de astronautas de estas dos nacionalidades en comparación con el resto. Veamos qué nacionalidades nos encontramos antes y después de la disolución de la Unión Soviética que tuvo lugar en 1991:
Principales nacionalidades antes o en 1991:
astronauts %>%
filter(year_of_mission <= 1991) %>%
count(nationality, sort = TRUE)
## # A tibble: 23 x 2
## nationality n
## <chr> <int>
## 1 U.S. 295
## 2 U.S.S.R/Russia 135
## 3 Germany 4
## 4 France 3
## 5 Bulgaria 2
## 6 Afghanistan 1
## 7 Australia 1
## 8 Austria 1
## 9 Canada 1
## 10 Cuba 1
## # ... with 13 more rows
Principales nacionalidades después de 1991:
astronauts %>%
filter(year_of_mission > 1991) %>%
count(nationality, sort = TRUE)
## # A tibble: 26 x 2
## nationality n
## <chr> <int>
## 1 U.S. 559
## 2 U.S.S.R/Russia 138
## 3 Japan 19
## 4 Canada 17
## 5 France 15
## 6 China 14
## 7 Italy 13
## 8 Germany 12
## 9 U.K./U.S. 6
## 10 Switzerland 4
## # ... with 16 more rows
Estos datos corroboran, confirman y son coherentes con un hecho histórico conocido. Estados Unidos se impuso sobre la Unión Soviética en la carrera espacial. No es extraño, por ello, que la mayor parte de astronautas del dataset tengan nacionalidad norteamericana y que la agencia espacial de Estados Unidos, la NASA, predomine en los programas de selección de astronautas. Veamos cuántos de los programas del dataset corresponden a esta agencia:
Total de los programas de selección de la NAS:
nasa_selection <- astronauts %>%
filter(str_detect(
selection,
regex("nasa", ignore_case = TRUE)
))
nasa_selection %>%
count()
## # A tibble: 1 x 1
## n
## <int>
## 1 829
829 de las 1277 de observaciones.
¿Principales pogramas de selección que no son de la NASA?:
astronauts %>%
filter(selection %nin% nasa_selection$selection) %>%
count(selection, sort = TRUE)
## # A tibble: 131 x 2
## selection n
## <chr> <int>
## 1 NPOE-4 15
## 2 TsPK-8 15
## 3 TsPK-12 14
## 4 TsPK-2 14
## 5 TsPK-5 14
## 6 TsPK-1 13
## 7 TsPK-6 12
## 8 China-1 11
## 9 TsKBEM-3 11
## 10 TsPK-3 11
## # ... with 121 more rows
La siguiente agencia que predomina en los programas de selección es TsPK. Tras una consulta en Google comprobamos que estas siglas hacen referencia al centro de entrenamiento de cosmonautas o Tsentr Podgotovki Kosmonavtov (TsPK) Ruso, centro inaugurado en 1960. Veamos qué programas del dataset no pertenecen a ninguna de estas dos agencias:
¿Programas de selección que no son de la NASA o de TsPK?:
nasa_tspk_selection <- astronauts %>%
filter(str_detect(
selection,
regex("nasa|tspk", ignore_case = TRUE)
))
astronauts %>%
filter(selection %nin% nasa_tspk_selection$selection) %>%
count(selection, sort = TRUE)
## # A tibble: 111 x 2
## selection n
## <chr> <int>
## 1 NPOE-4 15
## 2 China-1 11
## 3 TsKBEM-3 11
## 4 RKKE-14 10
## 5 1983 NRC Group 9
## 6 1998 ESA Group 8
## 7 MKS 8
## 8 1992 CSA Group 7
## 9 1978 Intercosmos Group 6
## 10 CNES-2/EAC 6
## # ... with 101 more rows
Vamos a ver las principales nacionalidades de los astronautas seleccionados por programas de selección que no corresponden a TsPK o a NASA:
Programas de selección de astronautas distintos a NASA y TsPK:
astronauts %>%
filter(selection %nin% nasa_tspk_selection$selection) %>%
count(nationality, sort = TRUE)
## # A tibble: 35 x 2
## nationality n
## <chr> <int>
## 1 U.S.S.R/Russia 126
## 2 U.S. 39
## 3 Japan 20
## 4 Canada 18
## 5 France 18
## 6 Germany 16
## 7 China 14
## 8 Italy 11
## 9 Switzerland 4
## 10 Belgium 3
## # ... with 25 more rows
La gran mayoría de los astronautas seleccionados por estos programas son rusos. Esto se debe a que además de la agencia TsPK, existen otros organismos de este país que han llevado a cabo procesos de selección (TsKBEM, NPOE, RKKE, MKS). Tengamos además en cuenta que TsPK es el centro de entrenamiento de cosmonautas pero la agencia espacial rusa desde 1992 es Roscosmos.
rus<-astronauts %>%
filter(selection %nin% nasa_tspk_selection$selection) %>%
filter(nationality == "U.S.S.R/Russia") %>%
count(selection, sort = TRUE)
rus
## # A tibble: 38 x 2
## selection n
## <chr> <int>
## 1 NPOE-4 15
## 2 TsKBEM-3 11
## 3 RKKE-14 10
## 4 MKS 8
## 5 Korolyov-Group / Mishin-Group / TsKBEM-1 6
## 6 NPOE-7 6
## 7 NPOE-9 6
## 8 NPOE-10 5
## 9 NPOE-6 5
## 10 RKKE-15 5
## # ... with 28 more rows
En Estados Unidos también hay programas de selección de astronautas no llevados a cabo por la NASA pero son mucho más reducidos en número.
us <- astronauts %>%
filter(selection %nin% nasa_tspk_selection$selection) %>%
filter(nationality == "U.S.") %>%
count(selection, sort = TRUE)
us
## # A tibble: 25 x 2
## selection n
## <chr> <int>
## 1 PS 6
## 2 N/A 3
## 3 PS for Astro-1 3
## 4 1965 USAF MOL group 1 2
## 5 PS for Spacelab-2 2
## 6 PS for STS-42 2
## 7 PS for STS-43 2
## 8 PS for STS-73 2
## 9 1979 USAF group 1
## 10 1985 Teacher in Space 1
## # ... with 15 more rows
En vista a los datos decidimos que nuestro dataset final contendrá las agencias: NASA (Estados Unidos) y TsPK, TsKBEM, NPOE, RKKE y MKS (Unión Soviética/ Rusia). Deberemos aclarar esto en el gráfico final.
df_astronauts <- astronauts %>%
filter(str_detect(
selection,
regex("nasa|tspk|tskbem|npoe|rkke|mks", ignore_case = TRUE)
)) %>%
select(name, year= year_of_mission, nationality, selection)
Y por tanto habremos dejado fuera de nuestro análisis a los siguientes programas de selección:
out_astronauts <- astronauts %>%
filter(selection %nin% df_astronauts$selection) %>%
count(selection, sort = TRUE)
datatable(out_astronauts)
Grafiquemos
Llega el momento de realizar algunas visualizaciones en base al dataset generado (df_astronauts). En primer lugar conviene crear una nueva columna donde se distinga aquellos astronautas seleccionados por la NASA por las agencias rusas seleccionadas. A esta columna la llamaremos Selection_program.
df <- df_astronauts %>%
mutate(Selection_program = case_when(
str_detect(selection, regex("nasa", ignore_case = TRUE)) ~ "US.NASA",
str_detect(selection, regex("tspk|tskbem|npoe|rkke|mks", ignore_case = TRUE)) ~ "USSR/Russia.*",
TRUE ~ selection
))
En el primer gráfico representaremos el número de astronautas enviados a programas espaciales cada año distinguiendo entre los dos grandes grupos creados. Indicaremos con una línea vertical la fecha del fin de la Unión Soviética.
df %>%
ggplot() +
geom_bar(aes(x = year, fill = Selection_program, color = Selection_program),
alpha = 0.4) +
scale_fill_manual(values = c("US.NASA" = "blue", "USSR/Russia.*" = "red")) +
scale_color_manual(values = c("US.NASA" = "blue", "USSR/Russia.*" = "red"))+
geom_vline(xintercept = 1991, color = "grey20", size = 1.2) +
theme_minimal() +
theme(legend.position = "bottom",
legend.title = element_blank()) +
labs(title = "Astronauts who participated in a space mission before 15 January 2020",
subtitle = "Number of astronauts per year. The vertical line indicates the end of the USSR in 1991",
caption = "*: TsPK, TsKBEM, NPOE, RKKE y MKS \n Source: TidyTuesday 2020 (Week 29)",
x = "",
y = "count")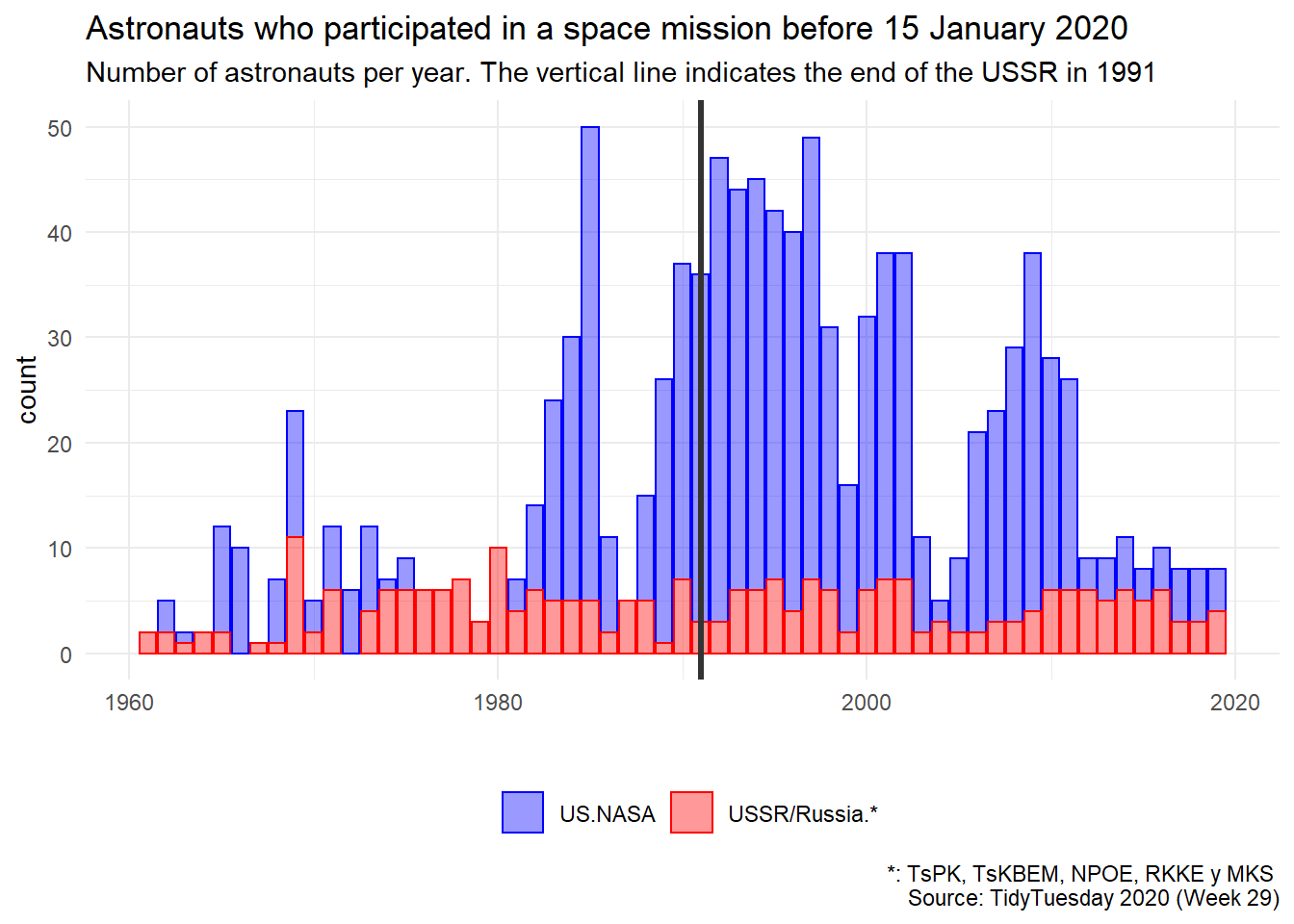
En el segundo gráfico representaremos la misma variable, es decir, el número de astronautas que han participado en misiones espaciales, pero en términos acumulados. La funcion cumsum() realiza esta operación de forma sencilla:
df_acumulado <- df %>%
group_by(Selection_program) %>%
count(year, Selection_program) %>%
mutate(acumulado = cumsum(n)) %>%
ungroup()
df_acumulado %>%
ggplot() +
geom_col(aes(x = year, y = acumulado, fill = Selection_program, color = Selection_program),
alpha = 0.4) +
scale_fill_manual(values = c("US.NASA" = "blue", "USSR/Russia.*" = "red")) +
scale_color_manual(values = c("US.NASA" = "blue", "USSR/Russia.*" = "red"))+
geom_vline(xintercept = 1991, color = "grey20", size = 1.2) +
theme_minimal() +
theme(legend.position = "bottom",
legend.title = element_blank()) +
labs(title = "Astronauts who participated in a space mission before 15 January 2020",
subtitle = "Cumulative number. The vertical line indicates the end of the USSR in 1991",
caption = "*: TsPK, TsKBEM, NPOE, RKKE y MKS \n Source: TidyTuesday 2020 (Week 29)",
x = "",
y = "cumulative")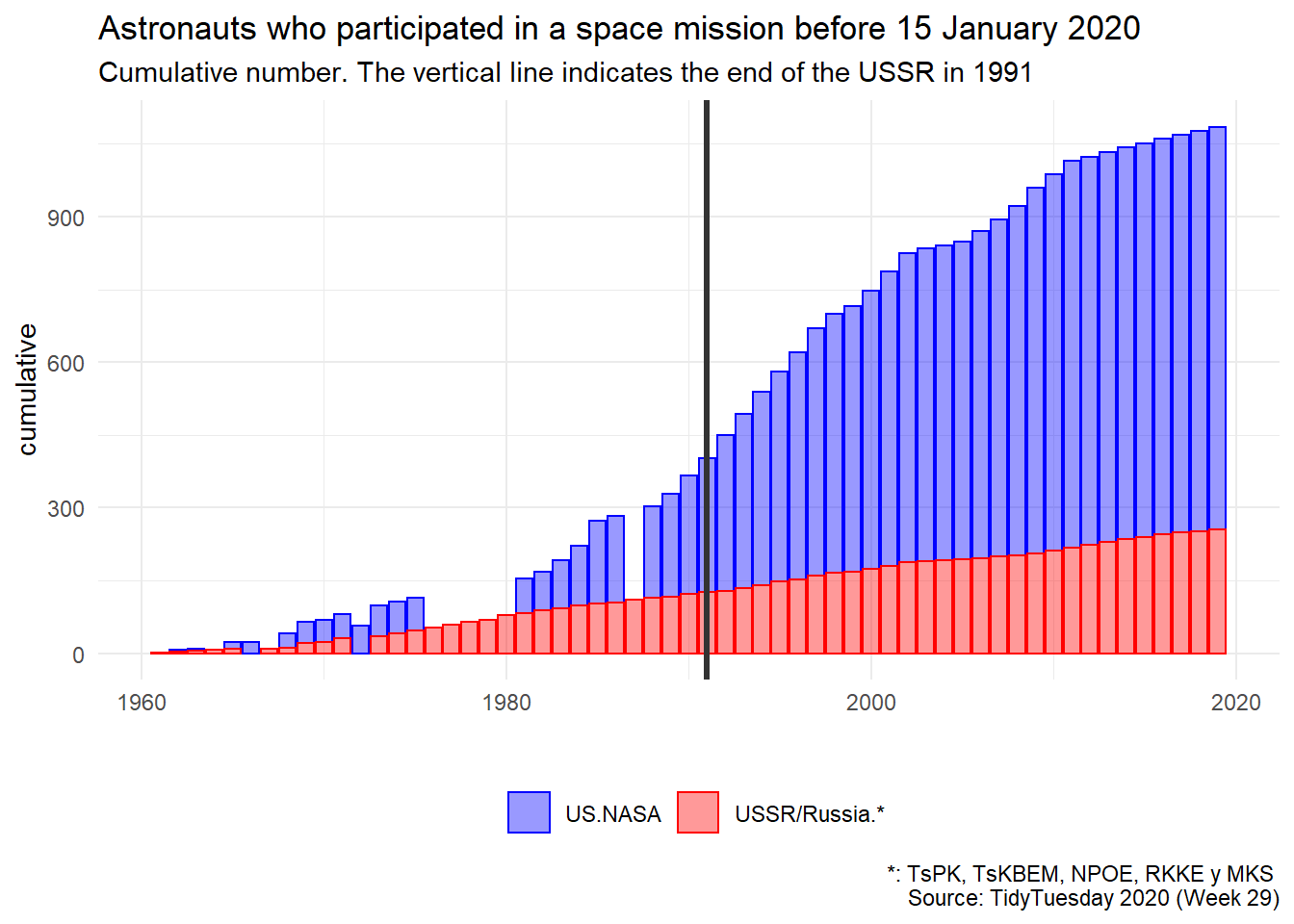
Hace unos días escribí dos entradas en mi blog sobre gráficos animados con {gganimate}. El primero de ellos trataba sobre la función view_follow() y en el segundo explicaba cómo añadir etiquetas a los gráficos animados. Considero que el caso en el que nos encontramos trabajando, donde se observa cierta rivalidad entre Estados Unidos y URSS-Rusia, podría ser un ejemplo adecuado para utilizar dicha función y donde añadir las etiquetas correspondientes. Vamos a ello a ver qué sale.
img <- readPNG("C:\\Users\\Usuario\\Desktop\\flag.png")
astro_plot <- df_acumulado %>%
ggplot(aes(x= year, y = acumulado, color = Selection_program)) +
background_image(img) +
geom_line(size = 1.5) +
geom_point(size = 3) +
geom_vline(xintercept = 1991, color = "grey20", size = 1.2) +
geom_label(aes(x= year, y = acumulado, label = Selection_program),
nudge_x = 1,
size = 3,
hjust = 0) +
labs(title = "Space Race. Astronauts who participated in a space mission",
subtitle= "Cumulative number. The vertical line indicates the end of the U.S.S.R.",
caption = "*: TsPK, TsKBEM, NPOE, RKKE y MKS \n Source: TidyTuesday 2020 (Week 29)",
y = "",
x = "") +
scale_color_manual(values = c("US.NASA" = "blue", "USSR/Russia.*" = "red")) +
transition_reveal(year) +
shadow_mark(past = FALSE) +
view_follow() +
enter_appear(early = FALSE) +
enter_grow() +
enter_fade(alpha = 0) +
theme_minimal() +
theme(panel.grid.major.x = element_blank(),
plot.title = element_text(size = 25,
face = "bold",
hjust = 0,
color = "grey80"),
plot.subtitle = element_text(size=20,
face = "bold",
hjust = 0,
color = "orange"),
plot.background = element_rect(fill = "black"),
axis.text = element_text(color = "grey80", size = 12),
plot.caption = element_text(color = "grey80",
size = 10),
plot.margin= unit(c(t = 1, r = 2, b = 1, l = 1), "cm"),
legend.position = "none")
animate(astro_plot, nframes= 80, width = 1000, height= 600, fps = 7)